Pytorch LayerNorm源码详解
1. LayerNorm使用介绍
pytorch中的函数定义如下:
1 | torch.nn.LayerNorm(normalized_shape, eps=1e-05, elementwise_affine=True, device=None, dtype=None) |
函数参数说明如如下: * normalized_shape:
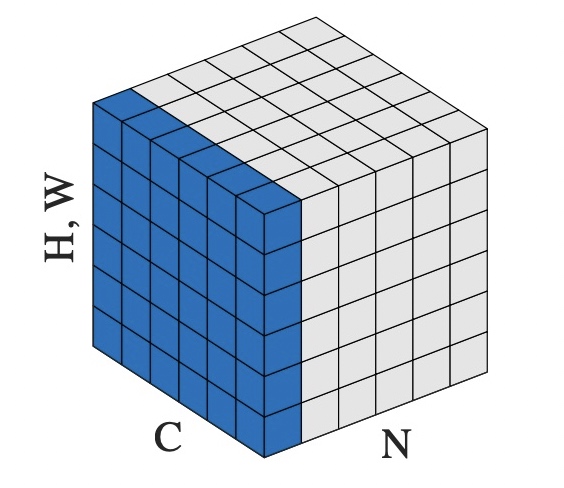
进行LayerNorm的维度定义,对于一个多维矩阵[N, C, H, W]来说,这里的normalized_shape定义都是要和矩阵最后几个维度保持一致的,这里就是[C, H, W]。对比数学公式,其中的
\(\gamma\) 和 \(\beta\)
的维度都是[C, H, W],\(x\)
和 \(y\)
的维度都是[N, C, H, W]。 *
eps:为了防止计算公式中的分母为0,加上一个极小的数,默认值:
1e-5 *
elementwise_affine:设为True的时候,进行elementwise的仿射变换, \(\gamma\) 和 \(\beta\)
才会生效,在训练过程中做为参数会被学习更新,为False的话不生效。\(\gamma\) 所有元素初始为1, \(\beta\) 所有元素初始为0的。\(\gamma\) 在代码实现中对应 \(gamma\), \(\beta\) 在代码实现中对应 \(beta\)。
LayerNorm的数学公式定义如下:
\[\begin{align*} Y &= \frac{X - E[X]}{\sqrt{Var[X] + \epsilon}} * \gamma + \beta \end{align*}\]
pytorch使用示例,给定一个[N, C, H, W]的矩阵,在[C, H, W]维上进行LayerNorm操作:
1 | # Image Example |
2. LayerNorm反向推导公式
为了方便推导,eps先忽略,输入为一维矩阵。对应LayerNorm的数学公式定义如下, 其中\(x\)是由\([x_1, ...,x_i, ..., x_N]\)组成的一维向量, \(y\)是输出向量,维度跟\(x\)一样; \(E[x]\)是期望,简写为\(\mu\); \(Var[x]\)是方差【\(\frac{1}{N} \sum^N_{i=1}{(x_i-\mu)^2}\)】; 标准差【\(\sqrt{Var[x]}\)】简写为\(\sigma\)。
\[\begin{align*} y &= \frac{x - E[x]}{\sqrt{Var[x]}} * \gamma + \beta \\ &= \frac{x - \mu}{\sigma} * \gamma + \beta \\ &= \hat{x} * \gamma + \beta \\ \\ \mu &= \frac{1}{N}\sum^N_{j=1}{x_j} \\ \\ \sigma &= \left( \frac{1}{N} \sum^N_{j=1}{(x_j-\mu)^2} \right)^{\frac{1}{2}} \\ \\ \hat{x} &= \frac{x-\mu}{\sigma} \\ \\ \end{align*}\]
这里有三个地方需要求梯度(即需要进行求导),分别是对参数gamma\((\gamma)\)和beta\((\beta)\), 以及输入x的求导, 即\(\frac{\partial{l}}{\partial{\gamma}}\)、\(\frac{\partial{l}}{\partial{\beta}}\)、\(\frac{\partial{l}}{\partial{x}}\)。同时在计算 \(\frac{\partial{l}}{\partial{x}}\) 时会用到 \(\frac{\partial{\mu}}{\partial{x}}\),\(\frac{\partial{\sigma}}{\partial{x}}\),\(\frac{\partial{\hat{x}}}{\partial{x}}\)。
\[\begin{align*} \frac{\partial{l}}{\partial{\gamma_i}} &= \frac{\partial{l}}{\partial{y_i}} * \frac{\partial{y_i}}{\partial{\gamma_i}} \\ &= \frac{\partial{l}}{\partial{y_i}} * \frac{x_i - \mu}{\sigma} \\ \\ \frac{\partial{l}}{\partial{\beta_i}} &= \frac{\partial{l}}{\partial{y_i}} * \frac{\partial{y_i}}{\partial{\beta_i}} \\ &= \frac{\partial{l}}{\partial{y_i}} * 1 \\ \\ \frac{\partial{\mu}}{\partial{x_i}} &= \frac{1}{N} \\ \\ \\ \frac{\partial{\sigma}}{\partial{x_i}} &= \frac{1}{2} * \left( \frac{1}{N} \sum^N_{j=1}{(x_j-\mu)^2} \right)^{-\frac{1}{2}} * \frac{\partial{}}{\partial{x_i}} \left( \frac{1}{N} \sum^N_{j=1}{(x_j-\mu)^2} \right) \\ &= \frac{1}{2} * \sigma^{-1} * \frac{\partial{}}{\partial{x_i}} \left( \frac{1}{N} \sum^N_{j=1}{(x_j-\mu)^2} \right) \\ &= \frac{1}{2} * \sigma^{-1} * \frac{1}{N} * 2 * (x_i - \mu) \\ &= \sigma^{-1} * \frac{1}{N} * (x_i - \mu) \\ \\ \frac{\partial{\hat{x}}}{\partial{x_i}} &= \frac{\partial{(x_j - \mu)}}{\partial{x_i}} * \sigma^{-1} + (x_j - \mu) * (-1) * \sigma^{-2} * \frac{\partial{\sigma}}{\partial{x_i}} \\ &= \sigma^{-1} * (\delta_{ij} - \frac{\partial{\mu}}{\partial{x_i}}) + \sigma^{-2} * (x_j - \mu) * (-1) * \frac{\partial{\sigma}}{\partial{x_i}} \\ &= \sigma^{-1} * \delta_{ij} + \sigma^{-1} * (- \frac{1}{N}) + \sigma^{-2} * (x_j - \mu) * (-1) * \frac{\partial{\sigma}}{\partial{x_i}} \\ &= \sigma^{-1} * \delta_{ij} + \sigma^{-1} * (- \frac{1}{N}) + \sigma^{-3} * \frac{1}{N} * (x_j - \mu) * (x_i - \mu) * (-1) \\ &[当i和j相等时,\delta_{ij}=1,否则\delta_{ij}=0] \\ \\ \frac{\partial{l}}{\partial{x_i}} &= \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \frac{\partial{y_j}}{\partial{x_i}} \\ &= \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \frac{\partial{y_j}}{\partial{\hat{x_j}}} * \frac{\partial{\hat{x_j}}}{\partial{x_i}} \\ &= \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * \left[ \sigma^{-1} * \delta_{ij} + \sigma^{-1} * (- \frac{1}{N}) + \sigma^{-3} * \frac{1}{N} * (x_j - \mu) * (x_i - \mu) * (-1) \right] \\ \end{align*}\]
这里 \(\gamma_i/\beta_i\) 与 \(x_i\) 是一一对应的, 所以不用累加;但对于 \(x_i\) 参与了所有 \(y\) 的计算,反向的时候计算梯度也需要对涉及的所有的 \(y_i\) 相关的梯度进行累加。
3. 源码实现
代码仓版本:https://github.com/pytorch/pytorch/tree/v2.0.1
3.1 前向计算
在aten/src/ATen/native/native_functions.yaml中的定义如下:
1
2
3
4
5
6
7
8
9- func: native_layer_norm(Tensor input, SymInt[] normalized_shape, Tensor? weight, Tensor? bias, float eps) -> (Tensor, Tensor, Tensor)
dispatch:
CPU: layer_norm_cpu
CUDA: layer_norm_cuda
MPS: layer_norm_mps
CompositeExplicitAutograd: math_native_layer_norm
NestedTensorCPU, NestedTensorCUDA: nested_layer_norm
autogen: native_layer_norm.out
tags: core
这里以layer_norm_cpu的实现为例,layer_norm_cpu定义在aten/src/ATen/native/layer_norm.cpp中。
在layer_norm_cpu的前向函数中,会根据input和normalized_shape进行shape的转换计算,从多维矩阵转为\(M \times
N\)的二维矩阵,比如input的shape是[2, 3, 4, 5],normalized_shape是[4, 5],
那么M=2*3=6, N=4*5=20;同时还会进行weight(对应\(gamma\))和bias(对应\(beta\))矩阵的初始化。
1 | std::tuple<Tensor, Tensor, Tensor> layer_norm_cpu( |
LayerNormKernel定义在aten/src/ATen/native/cpu/layer_norm_kernel.cpp中,实际的实现是LayerNormKernelImplInternal,
定义如下:
1 | template <typename T, typename T_ACC> |
在LayerNormKernelImplInternal首先了解at::parallel_for函数的使用,它的基本作用是对输入先进行分块,然后通过多线程进行并行处理,如下函数的定义是对[0,
M]分成多段,分别调用匿名函数。
1 | at::parallel_for(0, M, 1, [&](int64_t start, int64_t end) {...}) |
回顾下前向计算过程:
\[\begin{align*} y &= \frac{x - E[x]}{\sqrt{Var[x]+eps}} * \gamma + \beta \\ &= \frac{x - \mu}{\sigma} * \gamma + \beta \\ &= (\frac{x}{\sigma} + \frac{- \mu}{\sigma}) * \gamma + \beta \\ \end{align*}\]
匿名函数逻辑中,对于
M * N的矩阵,每次处理N个元素进行LayerNorm操作。mean对应\(\mu\), rstd_val和scale对应\(\frac{1}{\sigma}\), bias对应\(\frac{-\mu}{\sigma}\), 因此, \(y=(x * scale + bias) * gamma + beta\)
1 | for (const auto i : c10::irange(start, end)) { |
3.2 反向计算
对于多维矩阵求反向,可以看成是M个大小为N的向量,以一个5维向量为例,向量维度为\([M_1, M_2, C, H,
W]\),layer_norm的维度是\([C, H,
W]\),对应的\(M=M_1*M_2\), \(N=C*H*W\)
在aten/src/ATen/native/native_functions.yaml中的定义如下:
1
2
3
4
5
6
7- func: native_layer_norm_backward(Tensor grad_out, Tensor input, SymInt[] normalized_shape, Tensor mean, Tensor rstd, Tensor? weight, Tensor? bias, bool[3] output_mask) -> (Tensor, Tensor, Tensor)
dispatch:
CPU: layer_norm_backward_cpu
CUDA: layer_norm_backward_cuda
MPS: layer_norm_backward_mps
autogen: native_layer_norm_backward.out
tags: core
这里以layer_norm_backward_cpu的实现为例,layer_norm_backward_cpu定义在aten/src/ATen/native/layer_norm.cpp中。跟layer_norm_cpu类似,在backward中初始化相关tensor,和进行kernel的调用。
1 | std::tuple<Tensor, Tensor, Tensor> layer_norm_backward_cpu( |
为了方便和后续pytorch源码实现中对应,对上面推导公式的最后结果中做下相应的展开,展开如下: \[\begin{align*} \frac{\partial{l}}{\partial{x_i}} &= \sigma^{-1} * \frac{\partial{l}}{\partial{y_i}} * \gamma_i + (-1) * \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j + \sigma^{-3} * \frac{1}{N} * (\mu - x_i) * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (x_j - \mu) \\ &= \sigma^{-1} * \frac{\partial{l}}{\partial{y_i}} * \gamma_i + (-1) * \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j + \sigma^{-3} * \frac{1}{N} * \mu * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (x_j - \mu) + \sigma^{-3} * \frac{1}{N} * (- x_i) * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (x_j - \mu) \\ &= \sigma^{-1} * \frac{\partial{l}}{\partial{y_i}} * \gamma_i + (-1) * \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j + \sigma^{-3} * \frac{1}{N} * (-\mu) * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (\mu - x_j) + \sigma^{-3} * \frac{1}{N} * (x_i) * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (\mu - x_j) \\ &= \sigma^{-1} * \frac{\partial{l}}{\partial{y_i}} * \gamma_i + (-1) * \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j + \sigma^{-3} * \frac{1}{N} * (-\mu) * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (\mu - x_j) + \sigma^{-3} * \frac{1}{N} * x_i * \left[ \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * \mu - \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * x_j \right] \\ &= \gamma_i * \frac{\partial{l}}{\partial{y_i}} * \sigma^{-1} + \left[ -\sigma^{-3} * \frac{1}{N} * \mu * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (\mu - x_j) - \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j \right] + x_i * \left[ \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * \mu - \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * x_j \right] * \sigma^{-3} * \frac{1}{N} \\ \end{align*}\]
kernel的实现在是aten/src/ATen/native/cpu/layer_norm_kernel.cpp文件的LayerNormBackwardKernelImplInternal函数中,实现分为两个阶段:
- 初始化一个shape大小为
{2, max_threads, N}的buffer矩阵,对应其中的buffer[0]用于dgamma_buffer,buffer[1]用于dbeta_buffer。多线程分别计算dY和X。 - 对
dgamma/dbeta的值进行累加操作,复用X[i]和dY[i]
对于代码实现是通过两层嵌套进行的,对于第一步来说,最外面是对 \(M*N\)
的矩阵按行进行多线程并行,每个线程处理 \(m_i*N\)
个元素;第二步是按N列进行元素的累加。layer_norm_backward_frame函数中包含了主要的计算逻辑,
后面进一步分析。
1 | template <typename T> |
layer_norm_backward_frame函数中计算dgamma的逻辑如下,对应公式:\(\frac{\partial{l}}{\partial{\gamma_i}}
= \frac{\partial{l}}{\partial{y_i}} * \frac{x_i -
\mu}{\sigma}\), 其中 \(a=\frac{1}{\sigma}\), \(b=\frac{-\mu}{\sigma}=-a*\mu\)。
1 | if (!dgamma_null) { |
layer_norm_backward_frame函数中计算dbeta的逻辑如下,对应公式:\(\frac{\partial{l}}{\partial{\beta_i}}=
\frac{\partial{l}}{\partial{y_i}}\)。
1 | if (!dbeta_null) { |
layer_norm_backward_frame函数中计算dx的逻辑如下,对应公式:
\[\begin{align*} \frac{\partial{l}}{\partial{x_i}} &= \gamma_i * \frac{\partial{l}}{\partial{y_i}} * \sigma^{-1} + \left[ -\sigma^{-3} * \frac{1}{N} * \mu * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * (\mu - x_j) - \sigma^{-1} * \frac{1}{N} * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j \right] + x_i * \left[ \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * \mu - \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j * x_j \right] * \sigma^{-3} * \frac{1}{N} \\ \end{align*}\]
layer_norm_backward_frame函数核心代码实现如下:
1 | if (gamma_null) { |
代码中变量与公式对应关系如下: * ds对应\(\sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} *
\gamma_j * x_j\) * db对应\(\sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} *
\gamma_j\) * a对应\(\sigma^{-1}\) * scale对应\(\frac{1}{N}\) * b对应\(\left[ \sum_{j=1}^N
\frac{\partial{l}}{\partial{y_j}} * \gamma_j * \mu - \sum_{j=1}^N
\frac{\partial{l}}{\partial{y_j}} * \gamma_j * x_j \right] * \sigma^{-3}
* \frac{1}{N} = (db * \mu - ds) * a * a * a * scale\) *
c对应\(\left[ -\sigma^{-3} *
\frac{1}{N} * \mu * \sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} *
\gamma_j * (\mu - x_j) - \sigma^{-1} * \frac{1}{N} *
\sum_{j=1}^N \frac{\partial{l}}{\partial{y_j}} * \gamma_j \right]=-b *
\mu - db * a * scale\) *
最终结果:dx = Vec(a) * dy * gamma + Vec(b) * x + Vec(c)