paddle fluid版本代码解析
基本结构
Variable
定义在variable.h文件中,具体定义如下 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23class Variable {
public:
template <typename T>
const T& Get() const {
PADDLE_ENFORCE(holder_ != nullptr, "Variable must hold some thing");
PADDLE_ENFORCE(IsType<T>(),
"Variable must be type %s, the holding type is %s",
typeid(T).name(), holder_->Type().name());
return *static_cast<const T*>(holder_->Ptr());
}
template <typename T>
T* GetMutable() {
if (!IsType<T>()) {
holder_.reset(new PlaceholderImpl<T>(new T()));
}
return static_cast<T*>(holder_->Ptr());
}
...
std::unique_ptr<Placeholder>
holder_; // pointers to a PlaceholderImpl object indeed.
friend class Scope;
const std::string* name_;
};Placeholder用来真正保存分配的空间,
实现在PlaceholderImpl中。
Variable中的holder_保留了指向Placeholder实例的指针。每个variable都有一个string类型的名字保存在name_中,名字只在当前Scope空间中国年有效。
Scope
定义在scope.h文件中,具体定义如下 1
2
3
4
5
6
7
8
9
10
11
12
13class Scope {
public:
...
Variable* FindVar(const std::string& name) const;
const Scope& parent() const { return *parent_; }
const Scope* FindScope(const Variable* var) const;
...
private:
// Call Scope::NewScope for a sub-scope.
explicit Scope(Scope const* parent) : parent_(parent) {}
mutable std::unordered_map<std::string, Variable*> vars_;
mutable std::list<Scope*> kids_;
Scope const* parent_{nullptr};
RPC通信
paddle采用grpc作为底层的通信系统,paddle/operators/detail/send_recv.proto定义pserver收发消息的rpc消息接口,具体实现是在 recv_impl.cc中,头文件对应send_recv_impl.h。
pserver端请求收发
recv_impl.cc中SendRecvServerImpl类负责处理pserver端的rpc请求收发。定义如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28typedef std::pair<std::string, sendrecv::VariableMessage> MessageWithName;
class SendRecvServerImpl final : public SendRecvService::Service {
public:
explicit SendRecvServerImpl() {}
Status SendVariable(ServerContext *context, const VariableMessage *in_var,
VoidMessage *out_var) override;
Status GetVariable(ServerContext *context, const VariableMessage *in_var,
VariableMessage *out_var) override;
Status Wait(ServerContext *context, const VoidMessage *in_var,
VoidMessage *out_var) override;
void Reset();
void Done();
void SetScope(framework::Scope *scope) { scope_ = scope; };
const MessageWithName Get() { return this->var_recv_queue_.Pop(); }
void Push(const MessageWithName &msg) { this->var_recv_queue_.Push(msg); }
private:
// received variable from RPC, operators fetch variable from this queue.
SimpleBlockQueue<MessageWithName> var_recv_queue_;
framework::Scope *scope_;
// condition of the sub program
std::mutex mutex_;
bool done_;
std::condition_variable condition_;
};std::pair<std::string, sendrecv::VariableMessage>
mutex_, condition_, done_ 用来实现Wait接口的阻塞操作. 遗留问题:
SendRecvServerImpl::SendVariable从名字上理解是发送Variable,但实现里是直接把传入VariableMessage塞到了var_recv_queue_队列中。
1
2
3
4
5
6
7
8Status SendRecvServerImpl::SendVariable(ServerContext *context,
const VariableMessage *in_var,
VoidMessage *out_var) {
MessageWithName msg_with_name =
std::make_pair(in_var->varname(), std::move(*in_var));
var_recv_queue_.Push(std::move(msg_with_name));
return Status::OK;
}
trainer端请求收发
RPCClient类实现了trainer/worker端的rpc请求收发,定义: 1
2
3
4
5
6
7
8
9
10
11
12class RPCClient {
public:
RPCClient(std::shared_ptr<Channel> channel)
: stub_(SendRecvService::NewStub(channel)) {}
bool SendVariable(const framework::Scope &scope, const std::string &inname);
bool GetVariable(const framework::Scope &scope, const std::string &outname);
void Wait();
private:
std::unique_ptr<SendRecvService::Stub> stub_;
};SendVariable函数中做的事情是把本地Scope中名字为inname的Variable数据封装成一个VariableMessage发送给pserver。GetVariable函数中做的事情正好相反,从收到的rpc请求中取出名为outname的VariableMesage保存到本地的Scope中。
所有的Variable在收发的时候会通过SerializeToStream与DeserializeFromStream进行序列化与反序列化操作,不同类型的Variable的序列化函数定义在各自实现文件中,例如:lod_tensor.cc selected_rows.cc,公共的序列化操作定义在tensor_util.h文件中。
待开发计划:
目前不管是pserver还是trainer的GetVariable与SendVariable方法,固定传入的Place都是platform::CPUDeviceContext,这块后面会增加其他Place类型。
Operator
OperatorBase
OperatorBase是所有Op类的基类,所有Op都会实现对应的接口。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49class OperatorBase {
public:
OperatorBase(const std::string& type, const VariableNameMap& inputs,
const VariableNameMap& outputs, const AttributeMap& attrs);
virtual ~OperatorBase() {}
template <typename T>
inline const T& Attr(const std::string& name) const {
PADDLE_ENFORCE(attrs_.count(name) != 0, "%s should be in AttributeMap",
name);
return boost::get<T>(attrs_.at(name));
}
/// Net will call this function to Run an op.
virtual void Run(const Scope& scope, const platform::Place& place) const = 0;
// FIXME(typhoonzero): this is only used for recv_op to stop event_loop.
virtual void Stop() {}
virtual bool IsNetOp() const { return false; }
virtual bool SupportGPU() const { return false; }
/// rename inputs outputs name
void Rename(const std::string& old_name, const std::string& new_name);
const VariableNameMap& Inputs() const { return inputs_; }
const VariableNameMap& Outputs() const { return outputs_; }
//! Get a input with argument's name described in `op_proto`
std::string Input(const std::string& name) const;
//! Get a input which has multiple variables.
const std::vector<std::string>& Inputs(const std::string& name) const;
std::vector<std::string> InputVars() const;
//! Get a output with argument's name described in `op_proto`
std::string Output(const std::string& name) const;
//! Get an output which has multiple variables.
//! TODO add a vector_view to prevent memory copy.
const std::vector<std::string>& Outputs(const std::string& name) const;
virtual std::vector<std::string> OutputVars(bool has_intermediate) const;
const std::string& Type() const { return type_; }
const AttributeMap& Attrs() const { return attrs_; }
protected:
std::string type_;
// NOTE: in case of OpGrad, inputs_ contains:
// I (Inputs)
// O (Outputs)
// OG (Output Gradients)
VariableNameMap inputs_;
// NOTE: in case of OpGrad, outputs_ contains
// IG (Inputs Gradients)
VariableNameMap outputs_;
AttributeMap attrs_;
private:
void GenerateTemporaryNames();
void CheckAllInputOutputSet() const;
};
这里attrs_存储op的属性,inputs_与outputs_分别存储op的输入变量名称和输出变量名称,变量名称是string类型存储的,通过key(I,
O,
OG)的不同来区分不同的输入和输出。当Net中开始执行op的时候会调用op中的Run方法来执行。其中AttributeMap与VariableNameMap定义是在type_defs.h中,定义为
1
2
3
4
5
6
7using VariableNameMap = std::map<std::string, std::vector<std::string>>;
// The order should be as same as framework.proto
using Attribute =
boost::variant<boost::blank, int, float, std::string, std::vector<int>,
std::vector<float>, std::vector<std::string>, bool,
std::vector<bool>, BlockDesc*>;
using AttributeMap = std::unordered_map<std::string, Attribute>;
ExecutionContext
ExecutionContext是执行op的上下文环境的一个类,前面说OperatorBase中只保存了待操作变量的名称,这里ExecutionContext中就负责从对应Scope中把真是的Variable变量返回。以及可以返回Op对应的Attr内容。另外,在ExecutionContext也保存了platform::DeviceContext的执行设备的信息。
SendOp
sendOp相对简单,先举个简单的例子。 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41class SendOp : public framework::OperatorBase {
public:
SendOp(const std::string &type, const framework::VariableNameMap &inputs,
const framework::VariableNameMap &outputs,
const framework::AttributeMap &attrs)
: OperatorBase(type, inputs, outputs, attrs) {
// init client when the operator is created at runtime.
std::vector<std::string> endpoints =
Attr<std::vector<std::string>>("endpoints");
for (auto ep : endpoints) {
client_map_[ep].reset(new detail::RPCClient(
grpc::CreateChannel(ep, grpc::InsecureChannelCredentials())));
}
}
void Run(const framework::Scope &scope,
const platform::Place &dev_place) const override {
auto ins = Inputs("X");
auto outs = Outputs("Out");
std::vector<std::string> epmap = Attr<std::vector<std::string>>("epmap");
// TODO(typhoonzero): use async calls to send multiple variable asyncly.
for (size_t i = 0; i < ins.size(); ++i) {
bool ret = client_map_[epmap[i]]->SendVariable(scope, ins[i]);
if (!ret) {
LOG(ERROR) << "send variable error: " << ins[i];
}
}
// TODO(typhoonzero): support async optimization
client_map_[epmap[0]]->Wait();
for (size_t i = 0; i < outs.size(); ++i) {
bool ret = client_map_[epmap[i]]->GetVariable(scope, outs[i]);
if (!ret) {
LOG(ERROR) << "GetVariable error: " << outs[i];
}
}
}
protected:
mutable std::unordered_map<std::string, std::shared_ptr<detail::RPCClient>>
client_map_;
};client_map_保存所有跟pserver通信的Client,在初始化的时候根据endpoint进行初始化操作,Run方法真正开始执行的时候,根据X,
Out取出对应的输入输出变量名(这里key是固定的),从scope中取出对应的Variable,然后调用RpcClient的Send方法进行发送,目前是阻塞式的,每次只发一个变量,效率低,后续优化会改成异步发送。
OpKernelBase
1 | class OpKernelBase { |
OpKernelBase把ExecutionContext传入当成唯一的参数。OpKernelBase是Op计算函数的基类,依据是否包含kernel,可以将Op分为两种:包含Kernel的Op和不包含kernel的Op,前者Op的定义继承自OperatorWithKernel,后者继承自OperatorBase。在operator.h中专门定义有OperatorWithKernel是在OperatorBase中加入了OpKernelMap,接下来会举一个OpKearnel的例子。添加新op可参考文档
如何添加带kernel的Operator
MulOp
首先说说下注册,MulOp定义在mul_op.cc,
mul_op.h文件中,op在添加的时候需要进行注册操作。 1
2
3
4
5
6
7
8
9namespace ops = paddle::operators;
REGISTER_OPERATOR(mul, paddle::framework::OperatorWithKernel, ops::MulOpMaker,
ops::MulOpShapeInference,
paddle::framework::DefaultGradOpDescMaker<true>);
REGISTER_OPERATOR(mul_grad, ops::MulOpGrad);
REGISTER_OP_CPU_KERNEL(
mul, ops::MulKernel<paddle::platform::CPUDeviceContext, float>);
REGISTER_OP_CPU_KERNEL(
mul_grad, ops::MulGradKernel<paddle::platform::CPUDeviceContext, float>);1
2
3
4
5namespace ops = paddle::operators;
REGISTER_OP(mul, ops::MulOp, ops::MulOpMaker, mul_grad, ops::MulOpGrad);
REGISTER_OP_CPU_KERNEL(mul, ops::MulKernel<paddle::platform::CPUDeviceContext, float>);
REGISTER_OP_CPU_KERNEL(mul_grad,
ops::MulGradKernel<paddle::platform::CPUDeviceContext, float>);
MulOp具体的实现 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36class MulOpShapeInference : public framework::InferShapeBase {
public:
void operator()(framework::InferShapeContext* ctx) const override {
auto x_dims = ctx->GetInputDim("X");
auto y_dims = ctx->GetInputDim("Y");
int x_num_col_dims = ctx->Attrs().Get<int>("x_num_col_dims");
int y_num_col_dims = ctx->Attrs().Get<int>("y_num_col_dims");
....
ctx->SetOutputDim("Out", framework::make_ddim(output_dims));
ctx->ShareLoD("X", /*->*/ "Out");
}
};
class MulOpMaker : public framework::OpProtoAndCheckerMaker {
public:
MulOpMaker(OpProto* proto, OpAttrChecker* op_checker)
: OpProtoAndCheckerMaker(proto, op_checker) {
AddInput("X", "(Tensor), The first input tensor of mul op.");
AddInput("Y", "(Tensor), The second input tensor of mul op.");
AddOutput("Out", "(Tensor), The output tensor of mul op.");
...
};
template <typename DeviceContext, typename T>
class MulKernel : public framework::OpKernel<T> {
public:
void Compute(const framework::ExecutionContext& context) const override {
const Tensor* x = context.Input<Tensor>("X");
const Tensor* y = context.Input<Tensor>("Y");
Tensor* z = context.Output<Tensor>("Out");
......
math::matmul<DeviceContext, T>(
context.template device_context<DeviceContext>(), x_matrix, false,
y_matrix, false, 1, z, 0);
......
}
};
op的执行
所有的操作都是op的组合,在python中实现的时候所有的op都会append到Block中,然后通过proto格式发给具体实行的c++程序。在executor.py的run函数中会进行汇总,具体代码如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18def run(self,
program=None,
feed=None,
fetch_list=None,
feed_var_name='feed',
fetch_var_name='fetch',
scope=None,
return_numpy=True):
......
for i, var in enumerate(fetch_list):
global_block.append_op(
type='fetch',
inputs={'X': [var]},
outputs={'Out': [fetch_var]},
attrs={'col': i})
self.executor.run(program.desc, scope, 0, True, True)
......1
2
3
4
5
6
7
8
9
10
11
12
13for (auto& op_desc : block.AllOps()) {
auto op = paddle::framework::OpRegistry::CreateOp(*op_desc);
VLOG(3) << op->DebugStringEx(local_scope);
op->Run(*local_scope, place_);
if (FLAGS_check_nan_inf) {
for (auto& vname : op->OutputVars(true)) {
auto* var = local_scope->FindVar(vname);
if (var == nullptr) continue;
if (var->IsType<framework::LoDTensor>()) {
CheckTensorNANOrInf(vname, var->Get<framework::LoDTensor>());
}
}
}
带pserver的分布式实现
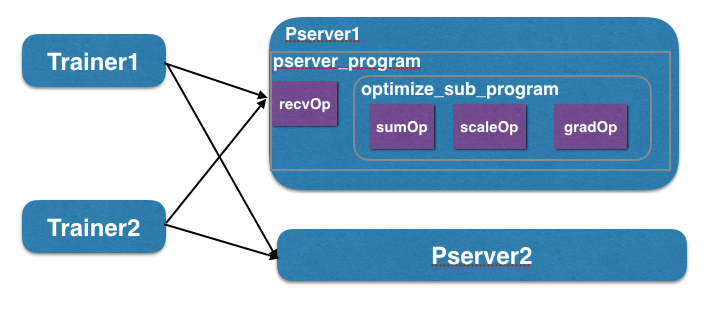
为了支持分布式版本的paddle训练,python中新增了DistributeTranspiler类,DistributeTranspiler的作用主要是optimization操作都放到了参数服务器上,在本地训练中的trainer上删除所有optimization操作。并针对trainer和pserver程序自动增加send_op操作。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24class DistributeTranspiler:
def transpile(self,
optimize_ops,
params_grads,
program=None,
pservers="127.0.0.1:6174",
trainers=1,
split_method=round_robin):
if program is None:
program = default_main_program()
self.program = program
self.trainers = trainers
self.optimize_ops = optimize_ops
self._optimize_distributed(
optimize_ops,
program,
params_grads,
pservers=pservers,
trainers=trainers,
split_method=split_method)
def get_trainer_program(self):#获取trainer程序
# remove optimize ops and add a send op to main_program
self.program.global_block().delete_ops(self.optimize_ops)
return self.program1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26def _optimize_distributed(self, optimize_ops, program, params_and_grads,
**kwargs):
if kwargs.has_key("split_method"):
split_method = kwargs["split_method"]
else:
split_method = round_robin
assert (callable(split_method))
pserver_endpoints = kwargs["pservers"].split(",")
self.param_grad_map = split_method(params_and_grads, pserver_endpoints)
send_op_ordered_inputs = []
send_op_ordered_outputs = []
epmap = []
for ep, v in self.param_grad_map.iteritems():
send_op_ordered_inputs.extend(v["grads"])
send_op_ordered_outputs.extend(v["params"])
for i in v["grads"]:
epmap.append(ep)
send_op = program.global_block().append_op(
type="send",
inputs={"X": send_op_ordered_inputs
}, # inputs is a list of tensors to be send
outputs={"Out": send_op_ordered_outputs},
attrs={"endpoints": pserver_endpoints,
"epmap": epmap})
1 | def get_pserver_program(self, endpoint, optimize_ops): |
pserver程序执行的时候需要先通过get_pserver_program获取pserver的program,这里一开始会先把split以后的参数拷贝到当前pserver_program的global_block里。保存所有梯度对应的变量名到grad_var_names中。通过_create_var_for_trainers在每个pserver上为每一个trainer都创建相同的变量,保存在optimize_sub_program的global_block中,同时也创建了一个用来合并所有trainer的变量merged_var。在optimize_sub_program添加了sum与scale的op操作用来合并计算的梯度。opt_op.inputs中如果有名为"Grad"的key的表明有针对Grad进行操作的新op需要进行append_op操作。最后一步操作是给pserver_program增加recv类型的op用来收取各个trainer发送过来的梯度内容。