ViT(Vision Transformer)论文阅读
1. ViT简介
ViT是2020年的一篇paper,目前(2023年2月)在google引用超11000次,CV图像领域中被广泛使用。在ViT出来之前,Transformer架构已经在NLP领域大显身手,在CV领域还是用的CNN,通过ViT这篇paper在CV中正式引入Transormer,且效果不错。
2. 网络介绍
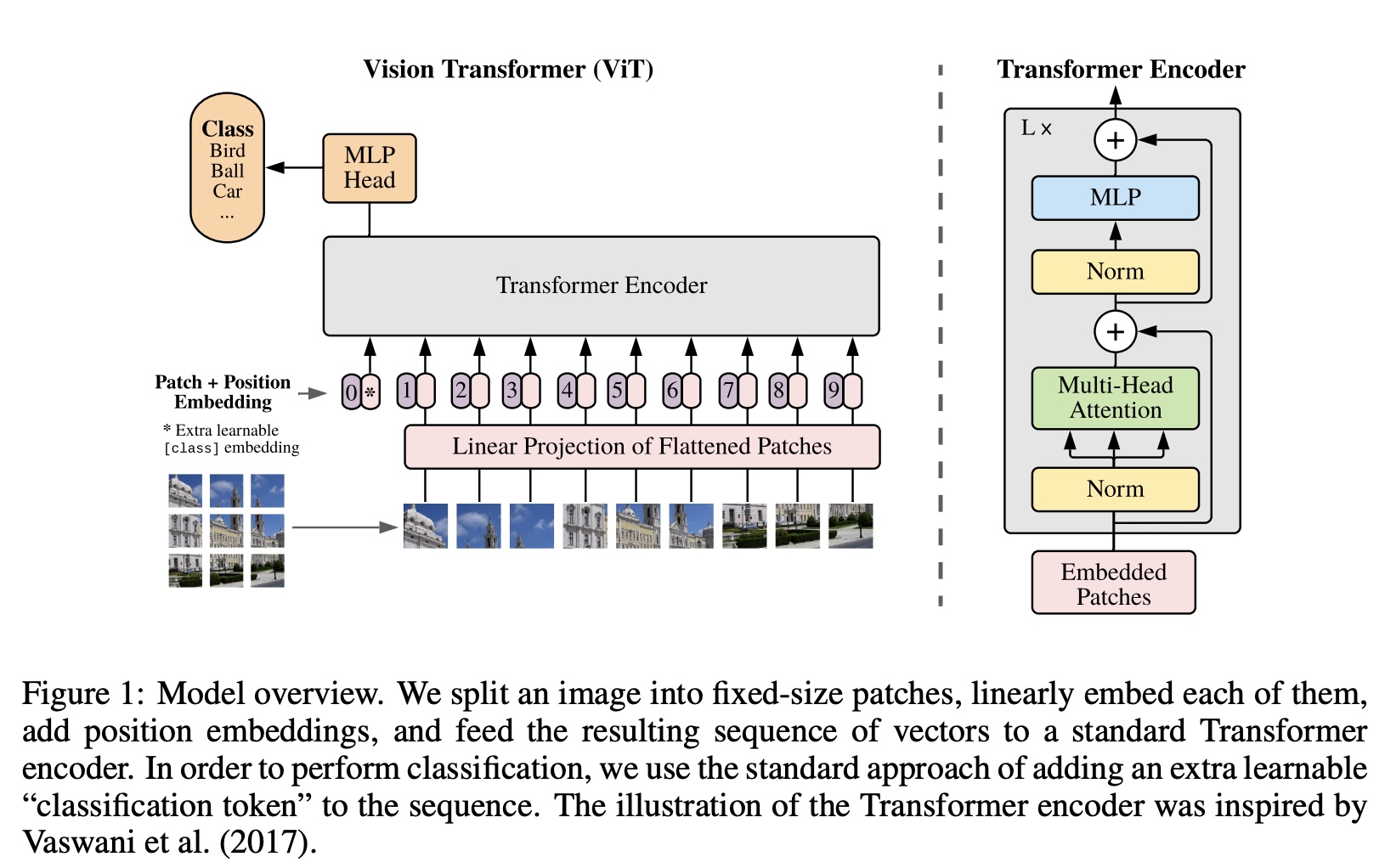
ViT基本思路是把图像分为多个图像切片(每个小切片称为一个patch),类似NLP中的一个词,多个patch拼接起来做为输入类似NLP中的Sequence。一张大小为(H*W*C)的图切分为N个大小为P*P*C的patch,其中P是patch切片的长宽,N等于H*W/(P*P)。
切片在输入的时候通过一个线性变换产出一个大小为D的隐式向量隐式编码后的Patch和位置信息一起进行embedding编码做为Encoder输入;类似BERT中的[class] token,
在Encoder输入中最前面补充了一个可学习的patch。
Transformer Encoder由多头self-attention结构加上MLP block结构组成,在每个block前加下Layernorm, 在每个block后加下residual连接。MLP是两层结构,采用非线性GELU做为激活函数。
公式表示如下: 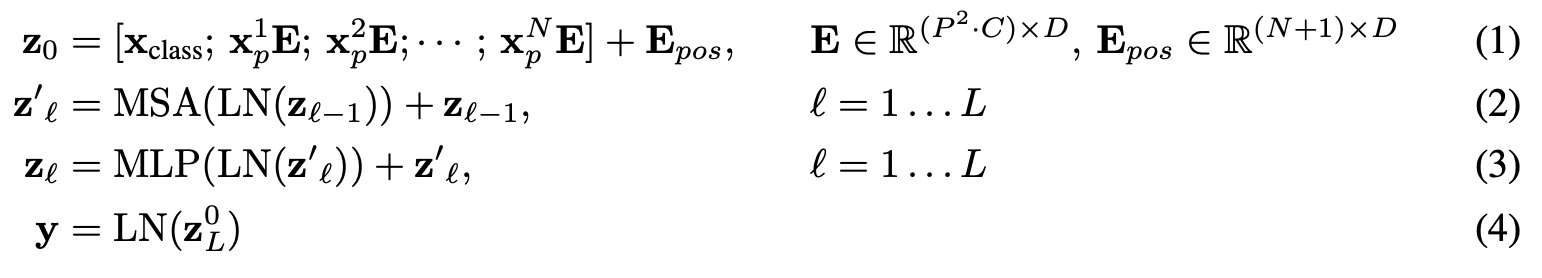
3. ViT与CNN结构的inductive bias比较
CNN能广泛适用图像原因在于它的inductive bias(归纳偏置),
inductive bias是关于目标函数的必要假设。
The inductive bias (also known as learning bias) of a learning algorithm is the set of assumptions that the learner uses to predict outputs of given inputs that it has not encountered.
对于CNN来说就是平移不变性(translation equivariance)和局部性(locality):
* 平移不变性从数学公式角度来说等价于
X(Y(input))=Y(X(input)),更直观角度是说对于输入图像的偏移处理也会导致对应输出结果的偏移。
*
局部性是说CNN只会考虑目标周围的特征,所以CNN对于全局特征处理不是太好。
ViT相比CNN来说,ViT中关于图像的inductive bias比较少,ViT结构中只有MLP层是有局部性和平移不变性的,self-attention层是全局的。ViT在大数据量训练下的效果很好。
4. 参数估计
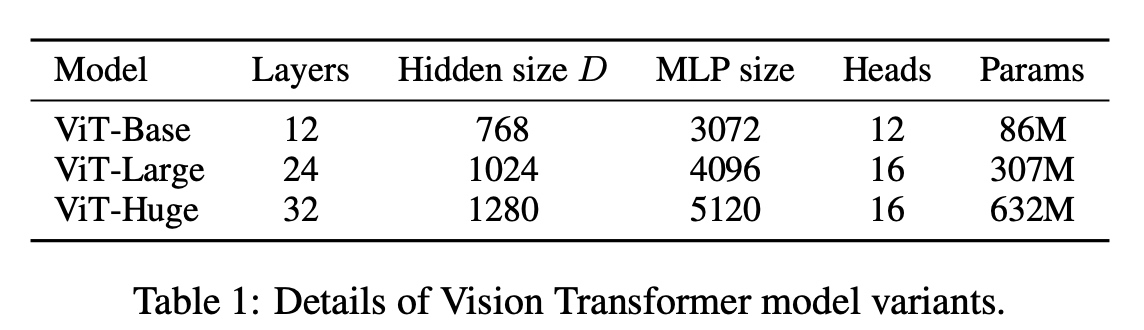
5. 使用介绍
参考vit-pytorch
进行代码分析, vit-pytorch中包含了很多vit的变种实现。
安装如下:
1 | $ pip install vit-pytorch |
使用示例: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16import torch
from vit_pytorch import ViT
v = ViT(
image_size = 256,
patch_size = 32,
num_classes = 1000,
dim = 1024,
depth = 6,
heads = 16,
mlp_dim = 2048,
dropout = 0.1,
emb_dropout = 0.1
)
img = torch.randn(1, 3, 256, 256)
preds = v(img) # (1, 1000)
参数介绍: * image_size: 图像大小 * patch_size:
切片大小,切片个数为n = (image_size // patch_size) ** 2,
n至少要大于16 * num_classes: 类别个数 * dim:
最后线性变换输出的维度大小,nn.Linear(..., dim) * depth:
Transformer中块的个数 * heads: 多头Attention中头的个数 * mlp_dim:
MLP层的维度 * channels: 图像的通道数 * dropout: dropout比率 *
emb_dropout: embedding层的droupout比率 * pool:
支持cls或mean两种pooling方式