Megatron-LM源码系列(六):Distributed-Optimizer分布式优化器实现Part1
1. 使用说明
在megatron中指定--use-distributed-optimizer就能开启分布式优化器,
参数定义在megatron/arguments.py中。分布式优化器的思路是将训练中的优化器状态均匀地分布到不同数据并行的rank结点上,相当于开启ZERO-1的训练。
1 | group.add_argument('--use-distributed-optimizer', action='store_true', |
在使用--use-distributed-optimizer, 同时会check两个参数
args.DDP_impl == 'local'(默认开启)和args.use_contiguous_buffers_in_local_ddp(默认开启)。
1 | # If we use the distributed optimizer, we need to have local DDP |
分布式优化器节省的理论显存值依赖参数类型和梯度类型,以下是每一个parameter对应占用的理论字节数(d表示数据并行的size大小,也就是一个数据并行中的卡数,
等于 \(TP \times PP\) ):
| 训练数据类型 | Non-distributed optim(单位Byte) | Distributed optim(单位Byte) |
|---|---|---|
| float16 param, float16 grads | 20 | 4 + 16/d |
| float16 param, fp32 grads | 18 | 6 + 12/d |
| fp32 param, fp32 grads | 16 | 8 + 8/d |
2. 实现介绍
Distributed-Optimizer分布式优化器的主要实现是通过连续的
grad buffer来进行的,grad buffer中用于模型状态和优化器状态之间进行parameter参数和grad梯度的通信。grad buffer中使用reduce-scatter和all-gather进行通信。数据流如下:
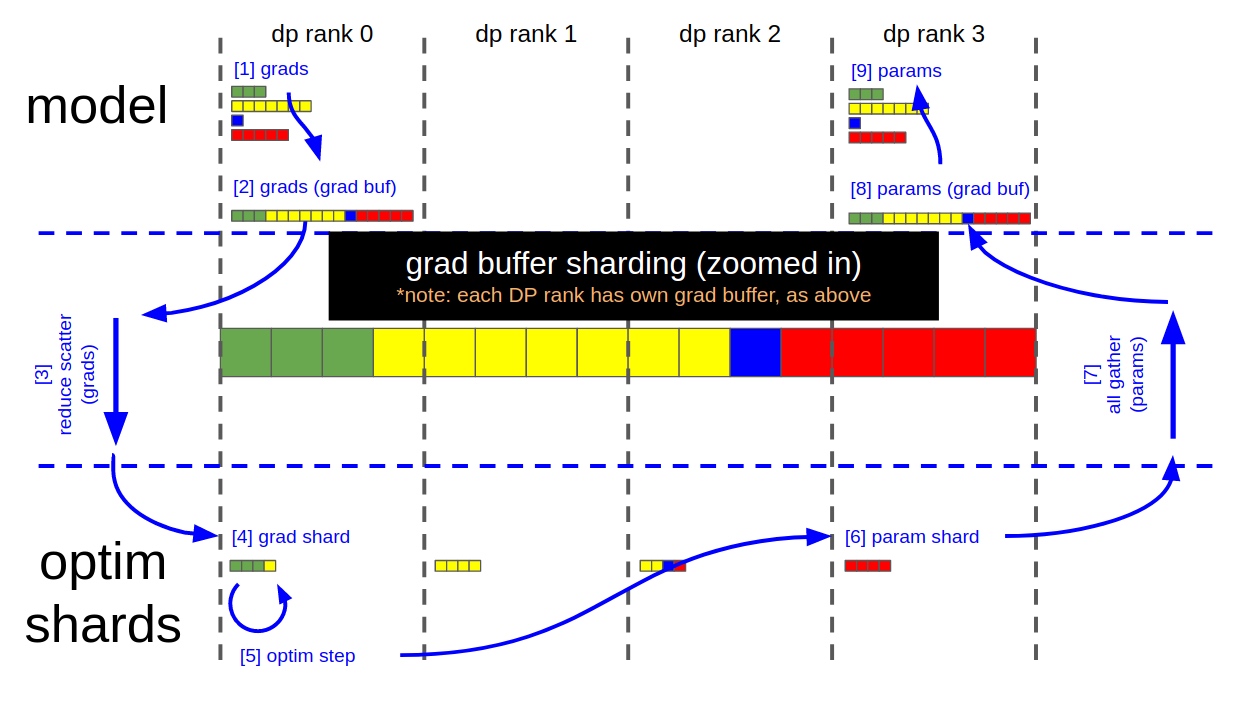
- 在每个dp的rank上计算完grad后,组成待更新的grad buffer数组
- 更新的时候通过reduce-scatter将grad buffer切分到各个rank上
- 在每个rank上完成优化器的step操作
- 最后将所有结果执行allgather操作得到更新后的grad buffer。
以fp16类型grad为例,grad buffer分片说明如下:
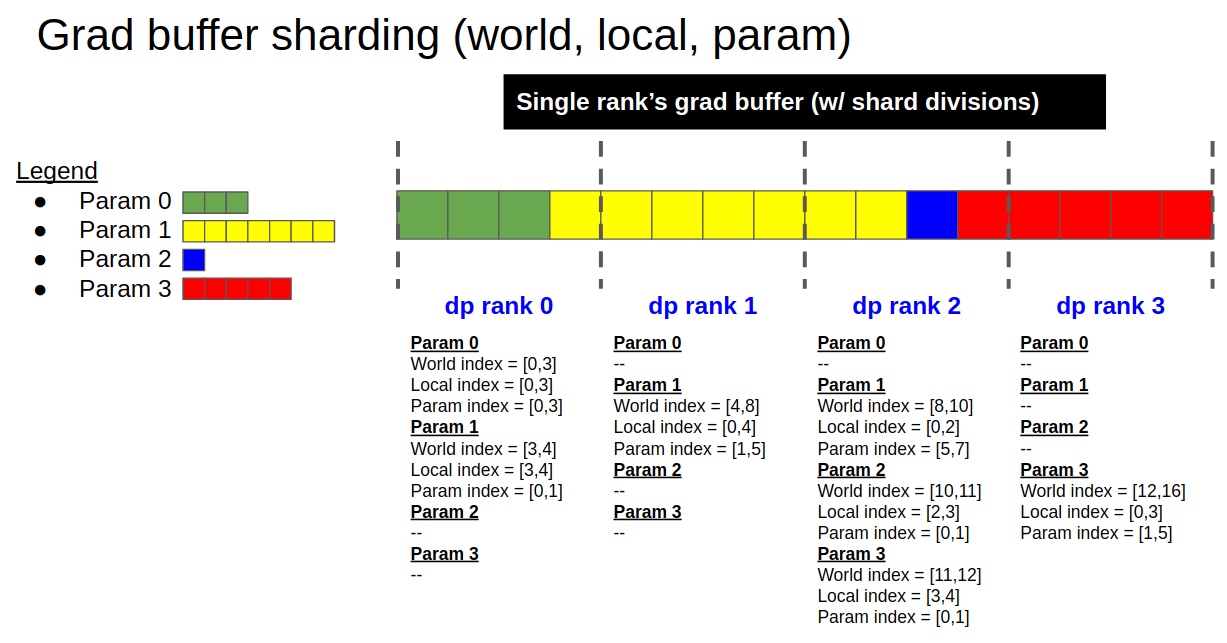
- 一共有4个参数,分别用绿/黄/蓝/红表示;总参数大小为16个fp16类型数据
- 按DP中rank的个数对总数据均匀切分
- 如果参数过大,每个rank可能会只包含部分参数的数据,所以要考虑参数的偏移
- 每个DP rank中的每个param参数都对应有3个偏移,一个是world_index表示总的数据偏移,一个是local_index表示在当前rank中的数据偏移,一个是param_index相对于param来说,表示当前rank结点存的数据的偏移。
- 以黄色参数Param1为例,在rank0存了Param1的一个元素,rank1存了Param1的4个元素;world_index来说rank0上黄色部分的元素是总数据的[3,4], rank1上黄色部分的4个元素是总数据的[4,8]; local_index来说在rank0上表示[3,4],rank1表示当前结点全部的4个元素,范围也就是[0,4];param_index来说,对于rank0上的Param1的param_index就是[0,1],在rank2上的param_index就是[1,5];
关键步骤详解:
- 上图中每个方块看成是一个grad buffer中的一个fp16类型元素,在反向结束以后,grad buffer中有16个fp16类型的元素
- 在每一个DP rank上调用reduce-scatter操作
- 每个DP rank的grad buffer中都有4个fp16类型元素经过了reduce-scatter操作更新,没更新的12个fp16类型元素等待后续垃圾回收
- 每个DP rank从grad
buffer中拷贝更新后的4个fp16类型元素到fp32类型的main grad
buffer中,准备开始后续的更新操作,例如
- DP rank0拷贝[0:4]个元素
- DP rank1拷贝[4:8]个元素
- DP rank2拷贝[8:12]个元素
- DP rank3拷贝[12:16]个元素
- 执行Optimizer.step(), step()操作必须通过fp32类型来进行计算
- 每个DP rank从main grad buffer中拷贝step()更新后的4个fp32类型元素到fp16类型的grad buffer中
- 执行allgather操作, 这样每个grad buffer就都是最新更新后的数据了
- 基于grad buffer来更新各个模型的fp16类型的参数
- 开始进行下一轮的更新
3. 源码实现
3.1 程序入口
- 初始化的入口在文件
megatron/training.py的get_model函数中,在创建LocalDDP的实例中会传入args.use_contiguous_buffers_in_local_ddp。
1 | from torch.nn.parallel.distributed import DistributedDataParallel as torchDDP |
- 训练的入口定义在
train_step函数中, 基本流程如下:
1 | def train_step(forward_step_func, data_iterator, |
3.2 grad buffer初始化(DistributedDataParallel类)
grad buffer初始化是在类DistributedDataParallel的init函数中, 源码定义在megatron/optimizer/distrib_optimizer.py文件中。
1 | class DistributedDataParallel(DistributedDataParallelBase): |
创建grad buffer和index map
1
2
3self._grad_buffers = {}
self._grad_buffer_param_index_map = {}
data_parallel_world_size = mpu.get_data_parallel_world_size()按类型分别计算每个类型元素的个数,使用type_num_elements map进行存储,key是元素类型,value是类型出现的元素个数
1 | # First calculate total number of elements per type. |
- 实际开始分配grad buffer,
为了支持被DP并行数正好切分,需要先对每个类型出现的个数进行padding操作;然后通过
MemoryBuffer进行存储的分配
1 | # Allocate the buffer. |
- 从grad
buffer中给每一个param参数分配对应的main_grad空间,在分配main_grad时根据每个param参数的类型从对应的
self._grad_buffers[dtype]中得到跟param.data.shape一样的tensor,这里的tensor与grad buffer共享存储。同时grad buffer的分配是按倒序来分配的,比如self.module.parameters()中有三个参数分别是[p1, p2, p3], 在grad buffer中存储则是[p3_grad, p2_grad, p1_grad]。_grad_buffer_param_index_map用来记录每个param的梯度在grad buffer中存储的起始和结束位置。
1 | ... |
- 遍历每一个参数,对于每一个参数的grad_fn的下一个function累加grad_acc函数进行改写,由于param本身没有
grad_fn,通过trick方式使用param.expand_as给param加上了grad_fn函数。
1 | ... |
3.3 分布式优化器实现(DistributedOptimizer类)
后续参考【Megatron-LM源码系列(七):Distributed-Optimizer分布式优化器实现Part2】