SwiGLU论文阅读
1. 论文
1.1 背景知识
SwiGLU是2019年提出的新的激活函数,它结合了SWISH和GLU两种者的特点。
1.1.1 SWISH: A SELF-GATED ACTIVATION FUNCTION
SWISH激活函数的定义如下,其中σ(x)是sigmoid函数(如下定义也称为SILU激活)
\[\begin{gather} f(x) = x \cdot \sigma{(x)} \\ \sigma{(x)} = (1 + exp(−x))^{-1} \end{gather}\]
SWISH激活函数是光滑且非单调,在x大于0时f(x)无上限,在x小于0时f(x)有下限,图如下:
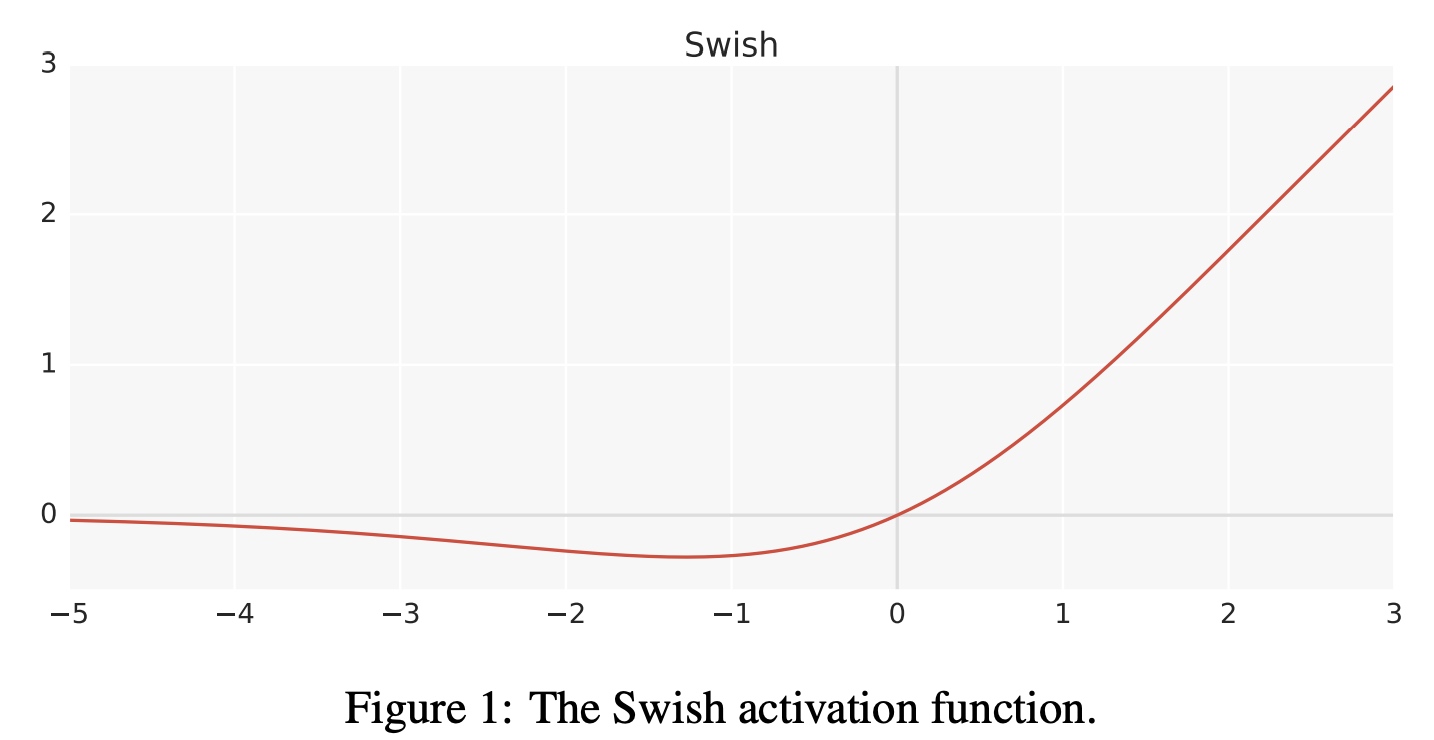
其他激活函数对比如下: 
SWISH激活函数的一次求导结果为:
1 | f'(x) = σ(x) + x · σ(x)(1 − σ(x)) |

1.1.2 GLU: Gated Linear Unit
GLU是Microsoft在2016年提出的,相比LSTM序列计算上有前后依赖不能很好并行,GLU是在conv基础上加上了gate的结构,可以实现stack堆叠,效果上比LSTM更好。
GLU的基础结构如下: 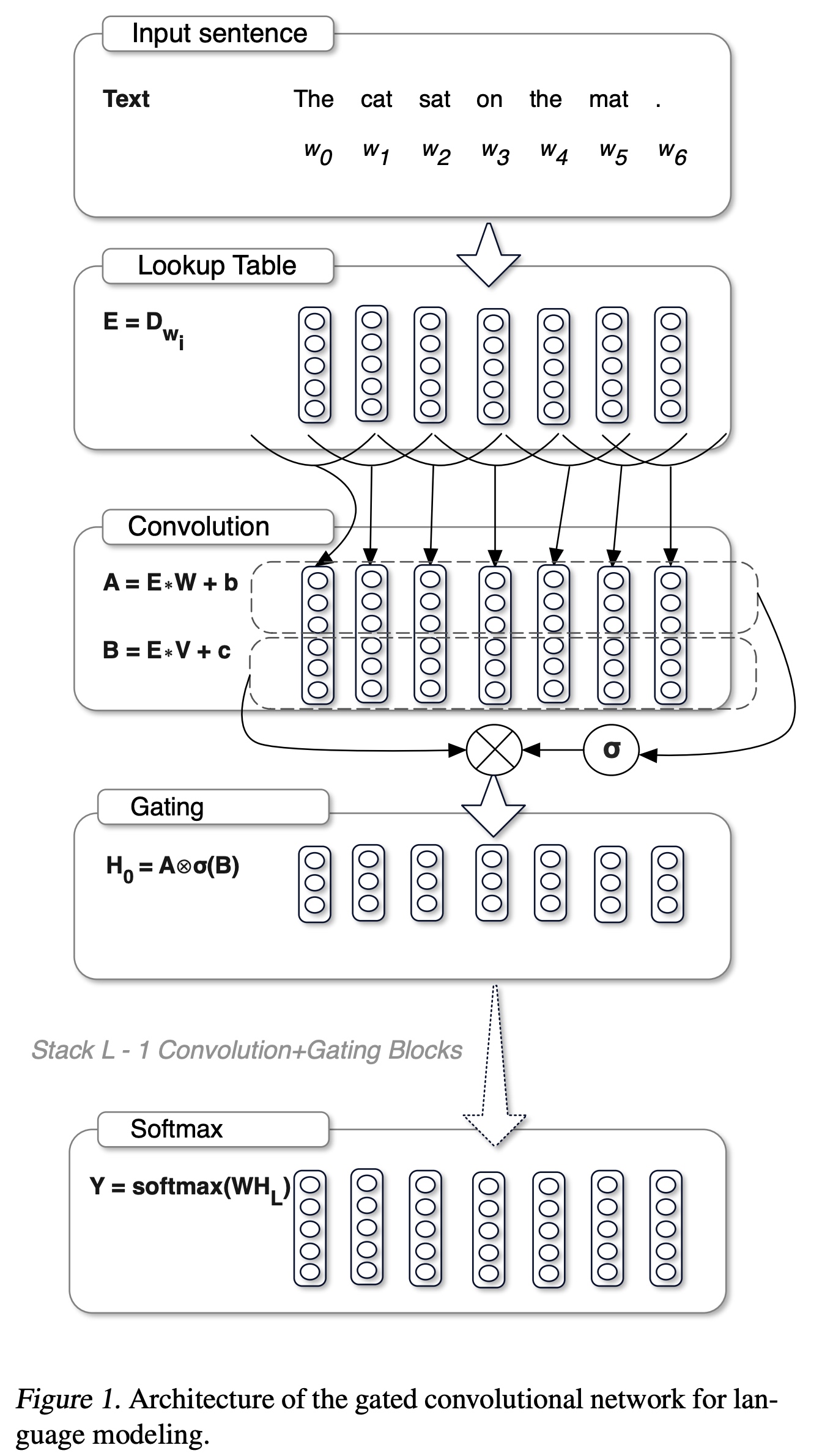
GLU的定义如下: 
在PyTorch中也有内置的GLU函数torch.nn.GLU(dim=-1),对应GLU(a,b)=a⊗σ(b),
其中a表示传入矩阵的前一半,b表示传入矩阵的后一半,
dim=-1表示从最后一维进行切分。跟论文中不同的是线性变换要用的话需要自己实现。
示例如下: 1
2
3
4import torch.nn as nn
m = nn.GLU()
input = torch.randn(4, 2)
output = m(input) # shape:[4, 1]
等价于如下: 1
2
3input_split = torch.split(input, 1, dim=-1)
sigmoid = nn.Sigmoid()
output = input_split[0] * sigmoid(input_split[1])
1.2 SwiGLU
SwiGLU主要是为了提升transformer中的FFN(feed-forward network)层的实现。FFN层的原始定义如下,其中使用了ReLU的激活:
1 | FFN(x, W1, W2, b1, b2) = max(0, xW1 + b1)W2 + b2 |
FFN的一些变种会使用不同的激活来替换ReLU: * 使用不带GLU的激活变种FFN如下,例如在T5中使用了不带bias的ReLU,也有使用GELU和Swish代替ReLU的FFN实现。
1 | FFN_ReLU(x, W1, W2) = max(xW1, 0)W2 |
- 使用带GLU的激活变种FFN如下:
1 | GLU(x, W, V, b, c) = σ(xW + b) ⊗ (xV + c) |