详解MegatronLM流水线模型并行训练(Pipeline Parallel)
1. 背景介绍
MegatronLM的第二篇论文【Efficient Large-Scale
Language Model Training on GPU ClustersUsing
Megatron-LM】是2021年出的,同时GPT-3模型参数已经达到了175B参数,GPU显存占用越来越多,训练时间也越来越长。
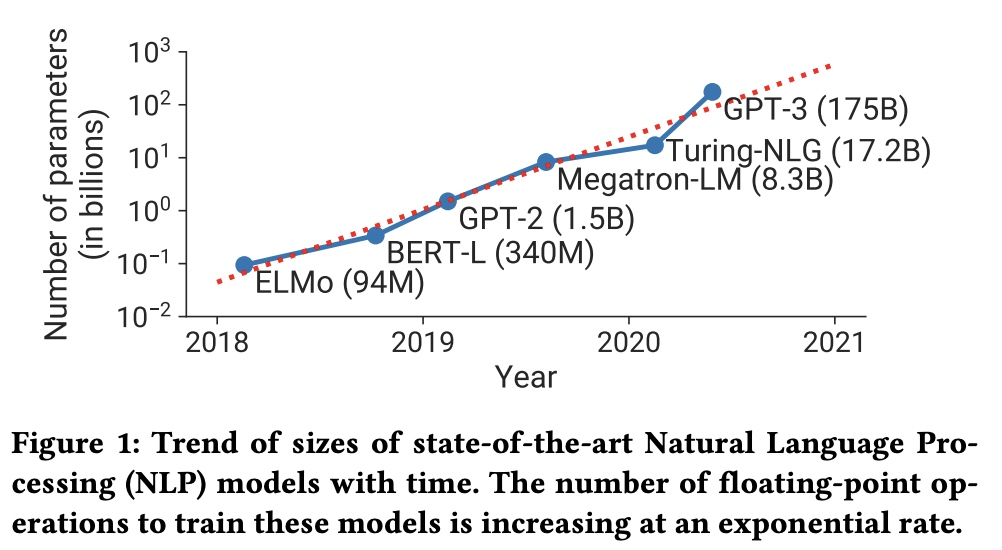
在本文中,MegatronLM结合了tensor模型并行、pipeline模型并行和数据并行来提升整体的训练速度,以及解决大模型在多机上的扩展性问题。在pipeline模型并行上提出了interleaved pipelining schedule方法,提升了10%的吞吐。
2. 并行方式介绍
2.1 数据并行(data parallel/DP)
每个work都有一份模型的完整拷贝,输入数据被分成了多个shard(份)分给不同work进行计算。work会定期汇总梯度信息,保证所有worker的权重一致。在大模型训练时,一张卡放不下整个模型,只能放下部分模型,一个大模型会分成多个shard(份)放在不同卡上。
2.2 Tensor并行(tensor parallel/TP)
复用了之前Megatron-1上的Tensor并行策略,transformer层分为自注意力和两层MLP组成,以MLP为例,原有 \(Y=GeLU(XA), Z=Dropout(YB)\) ; 由于GeLU是非线性的,所以这里对参数按列来切分 \(A=[A_1, A_2]\),得到 \(\left[ Y_1, Y_2 \right] = \left[ GeLU(XA_1), GeLU(XA_2) \right]\) ; 对于B按行来切分参数,\(B=\left[ {}_{B_2}^{B_1}\right], Y=\left[ Y_1, Y_2\right]\) 。

2.3 pipeline流水线模型并行(pipeline model parallel/PP)
通过pipeline并行, 一个模型可以被拆解为多份放到不同节点上, 以transformer为例,在transformer中block多次重复,所以每个device会分别处理相同个数的layer,对于非对称结构不好切分,这里不做考虑。如下图,不同TransformerLayer做为不同的pipeline的stage,也称为partition。
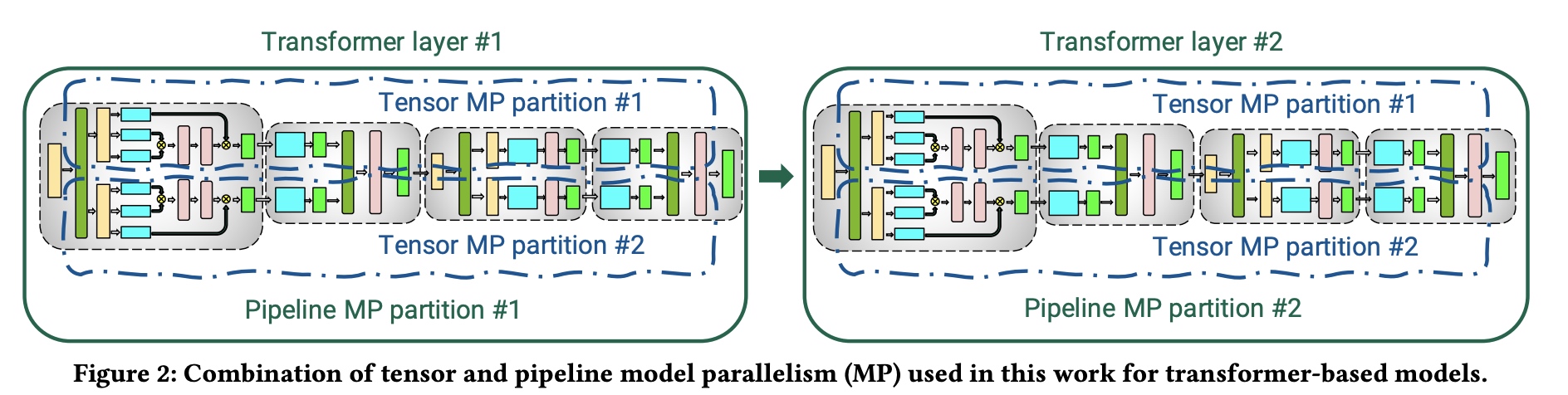
pipeline并行的基本思路是把一个batch切分为多个更小的microbatch,
多个microbatch同时并行训练,训练中要注意保证权重weight同步更新的语义。常见的pipeline有以下几种方式:
2.3.1 GPipe pipeline schedule。
Gpipe中重点有两块,一块是Mini-Batches改为了Micro-Batches;另一块是通过recompute方法在反向过程中降低显存占用,
主要是减少activation memory的占用(这里的activation指的是前向的输出结果,不是激活activation function)。
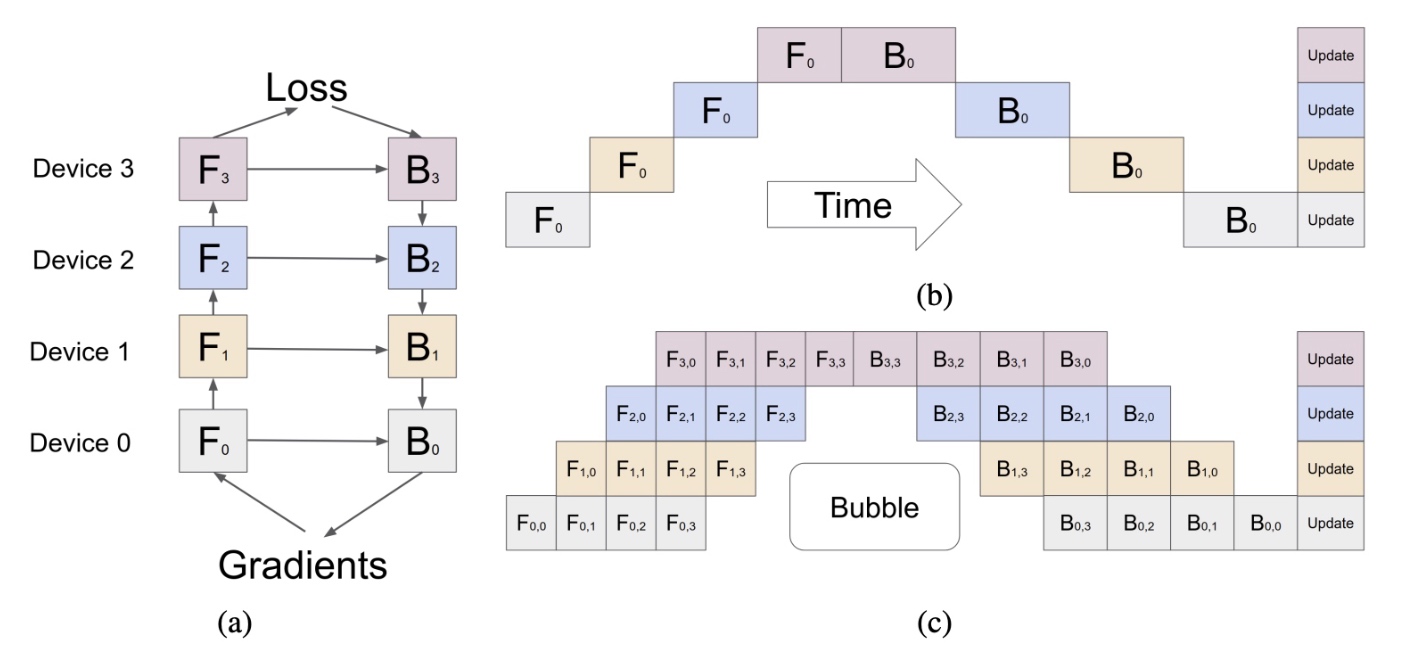
- a图:一个网络被分为4块,使用4个device来处理每一部分(每一部分包含若干layer),\(F_k\) 表示前向,\(B_k\) 表示后项,每一个 \(B_k\) 都会依赖对应前向 \(F_k\) 和 前一个后项的输出 \(B_{k+1}\) ;
- b图:展示一个
Mini-Batches的更新过程, 横轴表示时间,由于计算中存在上下依赖,会存在下方大面积的空白,空白部分也被称为Bubble, 这个图中有个问题是下标没有对应更新为0,1,2,3; - c图:当一个
Mini-Batches被分为4个Micro-Batches, 通过pipeline并行使用microbatch可以大幅减少Bubble,例如 \(F_{1,2}\) 依赖 \(F_{0,2}\), \(B_{1,2}\) 依赖 \(B_{2, 2}\) 和 \(F_{1, 2}\)。
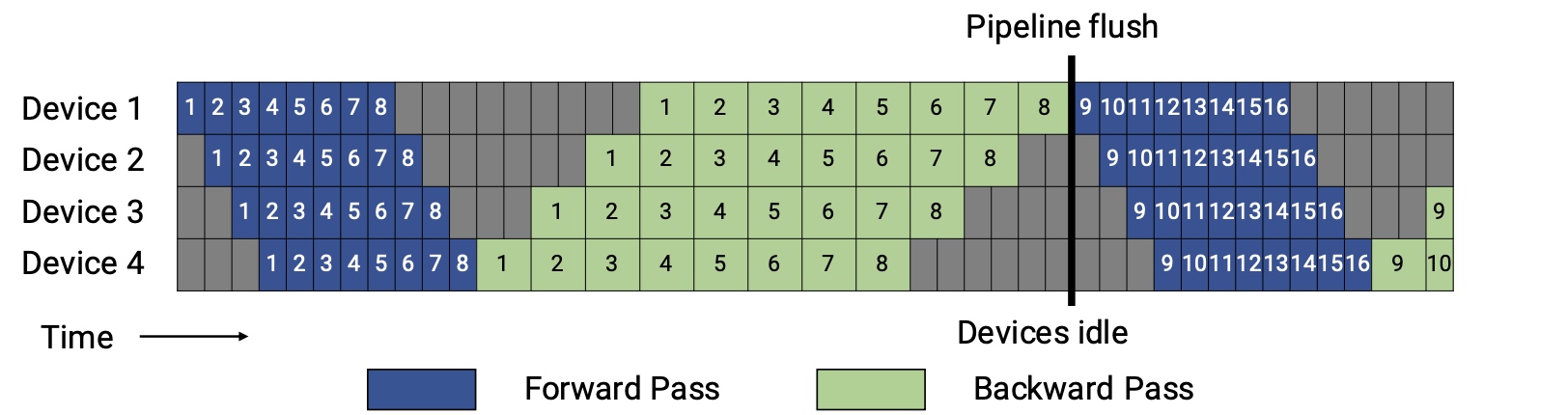
在GPipe中所有的microbatch的前向都先执行,然后再执行训练的后向。在所有前后向执行完后进行pipeline的flush操作。如图每个batch被切分为8个microbatch。这里假设反向的计算耗时是前向的两倍。
接下来计算下pipeline的bubble耗时与理想计算时间的占比(Bubble time fraction (pipeline bubble size)),pipeline的bubble耗时用
\(t_{pb}\) 表示,microbatche的大小用
\(m\) 表示,pipeline的stage个数用 \(p\) 表示,每个iter的理想时间用 \(t_{id}\)
表示,执行一个microbatch的前向和后向分别用 \(t_f\) 和 \(t_b\) 表示。
以第一个microbatch为例,在前向计算时bubble耗时有 \((p-1) \times t_f\), 后向计算时bubble耗时有 \((p-1) \times t_b\), 总的bubble耗时有 \(t_{pb} = (p-1) \times (t_f + t_b)\) , 理想的计算时间 \(t_{id} = m * (t_f + t_b)\)。最终理想计算耗时与bubble耗时的比例如下。为了降低占比就要增大 \(m\), 使得 \(m \gg p\) , 这时显存占用就会上升。 计算公式如下:
\[\begin{gather*} Bubble\ time\ fraction\ (pipeline\ bubble\ size) = \frac{t_{pb}}{t_{id}} = \frac{p-1}{m} \end{gather*}\]
通常情况下,会缓存记录下所有算子的前向计算结果,用于backward时的梯度计算,这部分结果的显存占用(activation memory)可能会比weight参数的显存占用还大。为了减少少这部分activation memory显存存占用,在GPipe中当进行反向计算时,第k个设备会重新计算前向的过程
\(F_k\)。通过重计算,activation memory从
\(O\left( N \times L \right)\) 降为了
\(O\left( N + \frac{L}{K} \times \frac{N}{M}
\right)\)。 \(L\) 表示总层数,
\(N\) 表示mini-batch的大小,\(M\) 表示micro-batch的个数。
在GPipe的结果中,
AmoebaNet通过重计算,activation memory从6.26G降为了3.46G;Transformer通过重计算每个device/accelerator可以训练模型参数量较之前大了2.7倍。
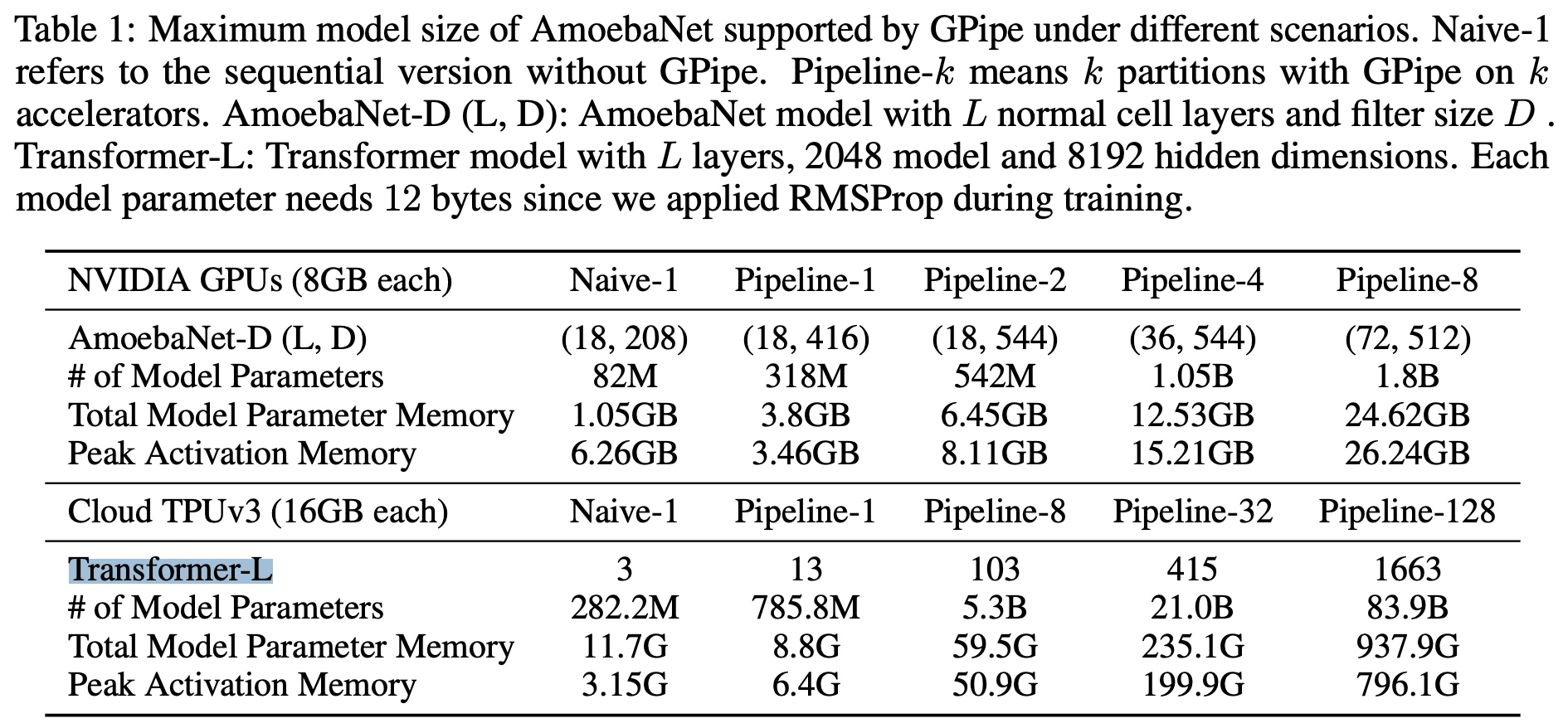
2.3.2 PipeDream
论文出自PipeDream: Generalized Pipeline Parallelism for DNN Training。
之前的pipeline并行先统一做所有前向再开始做后向,后向计算中会用到前向对应的输出(activation)和前一个算子的后向输出(这里叫成state状态)。存在问题在于前后向的state在不同batch中可能会被误用,也就是没有对应的版本区分。GPipe的方式存在问题在于频繁的pipeline flush也会降低效率。
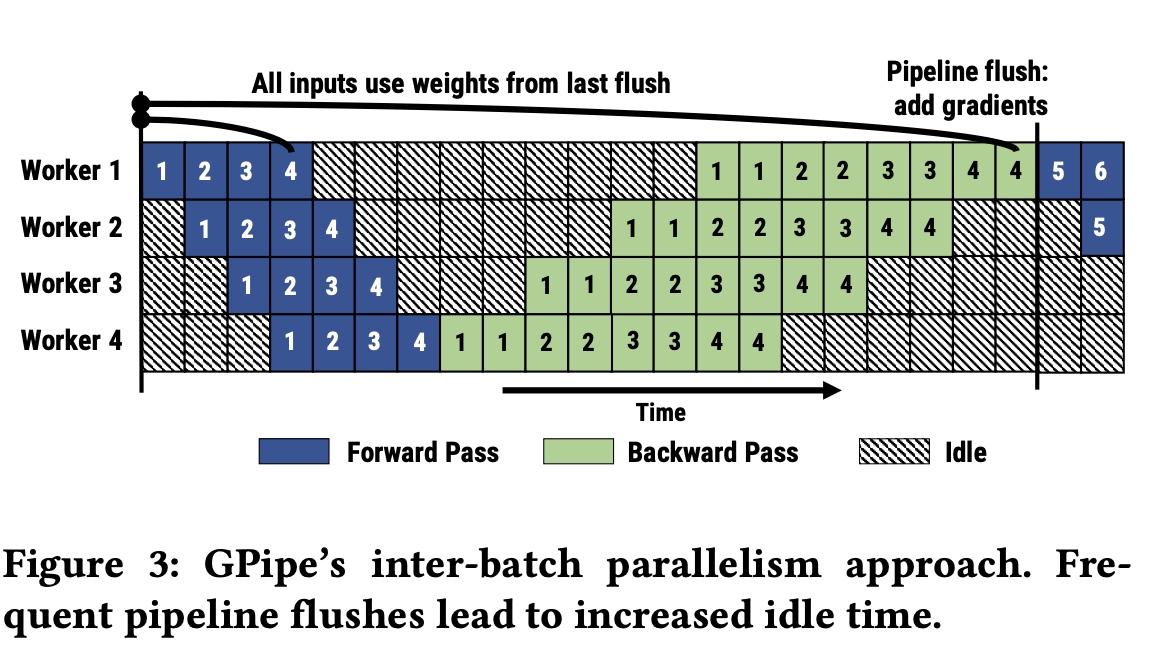
在PipeDream中有两个重点,一个是论文提出了1F1B算法进行并行的调度,使得硬件利用率在语义层面接近数据并行,不过跟数据并行不同的是在1F1B使用了不同版本的weight参数进行训练,在训练中避免了GPipe中定期的pipeline flush;另一个点是会自动进行pipeline
stage的切分。

对于1F1B算法实现来说,在前向startup计算中,每个stage计算完前向后会异步把输出结果发送给下一个stage;最后一个stage来说,会在前向计算完成后立马开始后向的计算(worker4完成蓝色块1的前向计算后,直接开始绿色块1的后向计算);steady稳定状态下,前向和后向是交替进行的,也就是1F1B。这样就不用在最后统一做梯度更新,每次PP(pipeline
parallel)执行过程中都只传一部分梯度和输出结果给一个worker,减少了通信量。对于采用数据并行的stage,通过round-robin方法分发数据,保证一个minibatch的数据是在同一个worker上的。
对于pipeline stage的切分,PipeDream先通过profile方式在一个GPU卡上跑1000个minibatch,统计每层的前向和后向计算耗时,每层的输出大小和weight权重大小,预估all-reduce等通信量。partition算法来确定:如何划分stage到worker、哪些stage需要复制进行数据并行,以及mini-batch的大小。
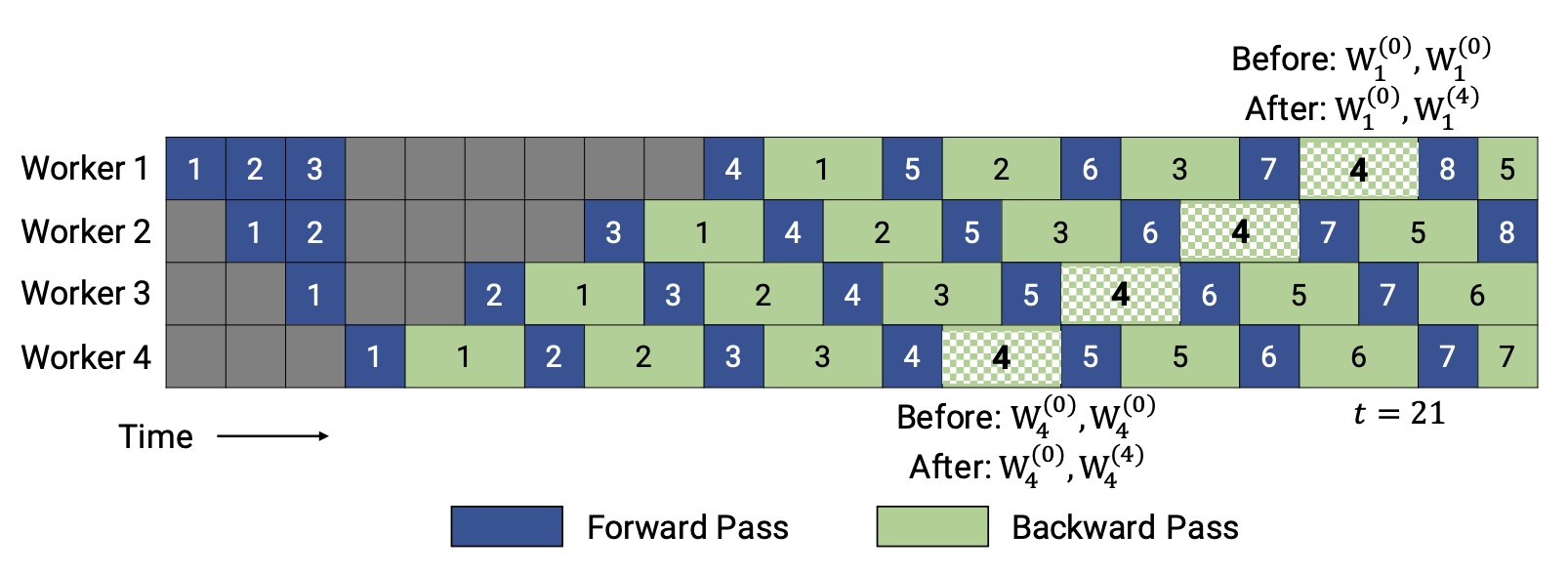
在之前的pipeline并行系统中,每个stage的前向和后向用到的参数都是不同的,这样可能会导致模型收敛问题。如图4中,mini-batch
5是在1的后向算完执行,但5的后向是在2,3,4的后向算完才执行,用到的参数不一样。因此在PipeDream中采用了weight stashing机制,前向stage每次都采用最新的参数处理minibatch,在前向算完后,计算完后保存参数提供给后向使用,保证一个stage内前向和后向用的参数是一致的,
如下图worker1(stage1)和worker3(stage3)中5的前向和后向都是用的一样的参数,不同stage的参数版本是不一样的。
同时还有一个vertical sync可选的方法,为了消除跨stage的不一致问题,意思跟weight stashing稍有不同是,在minibatch第一次进入pipeline
stage时采用最新参数版本,固定当前的参数版本,在后续stage计算中都采用跟第一个stage相同的参数版本,相当于按列固化stage的参数版本号。
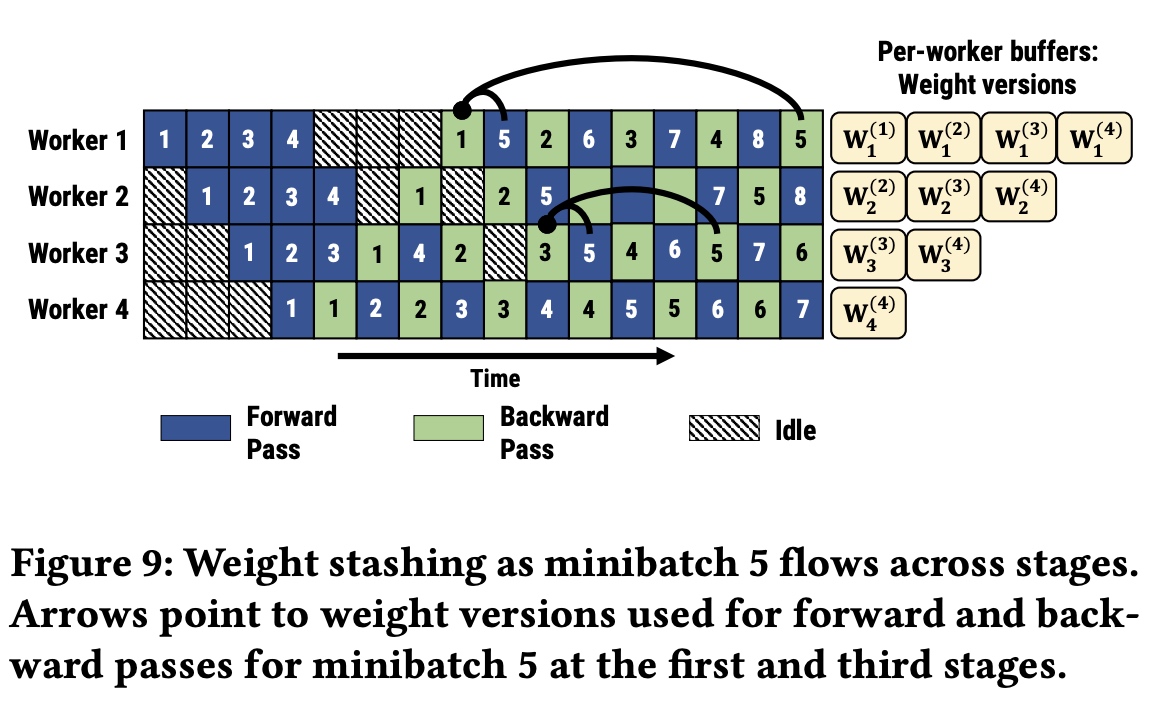
2.3.3 PipeDream-2BW
PipeDream-2BW重点关注降低显存占用和提升吞吐,是在PipeDream的后续,文中提出了两种pipeline调度方法来降低显存,一种是Double-buffered weight updates (2BW),另一种是PipeDream-Flush;同时PipeDream的Planner决定如何合理切分模型。
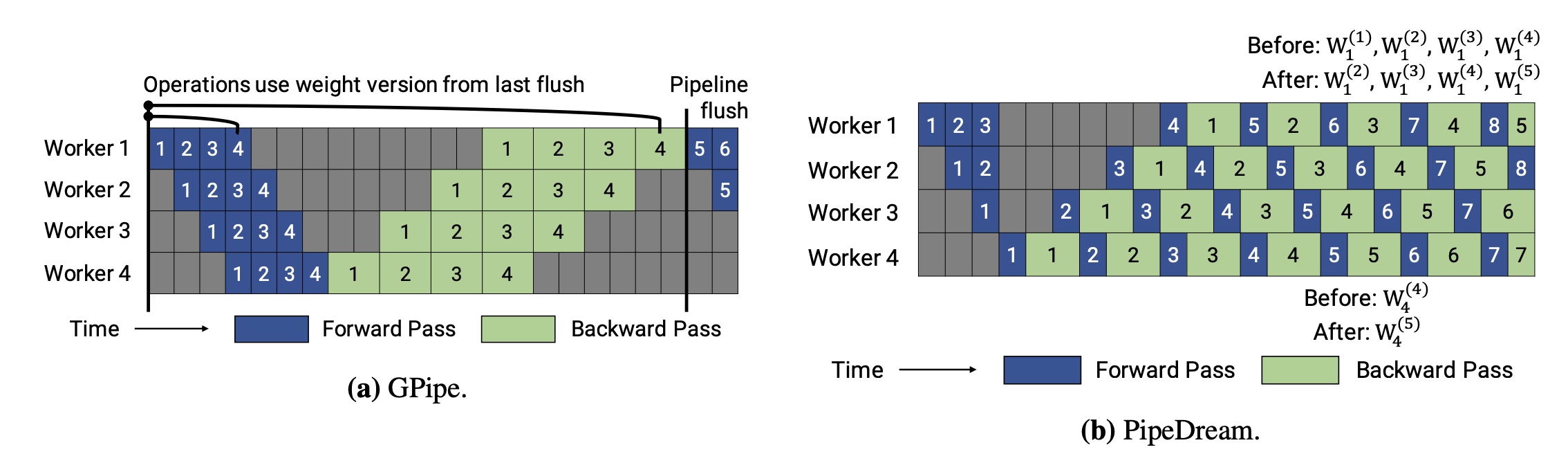 先回顾下GPipe和PipeDream的区别,再看和
先回顾下GPipe和PipeDream的区别,再看和PipeDream-2BW的比较。
* GPipe中只会保留一个版本的参数,同时在pipeline
flush的时候会更新参数;Gpipe中使用了micro-batch。 *
PipeDream中采用了1F1B方式,会同时保留多个版本的参数;PipeDream中用的还是mini-batch,不同的mini-batch分别更新。
\(Double\ buffered\ weight\ updates\
(2BW)\):在PipeDream-2BW中的粒度是micro-batch,
对于每个micro-batch在前向和后向过程中都是采用相同版本的参数进行计算。不同的是PipeDream-2BW最多只会保留两个版本的参数,减少显存占用。具体做法:每处理
\(m\) 个micro-batch( \(m \gg d\) , \(d\)
是pipeline的stage数,也就是pipeline的深度)会更新一版参数,下图示例中
\(m=d=4\)
。新版权重不是立马使用,而是等之前用老版本参数的micro-batch的反向计算完后,新的micro-batch再采用新版的参数。跟Gpipe相比,这里是每过
\(m\)
个micro-batch进行梯度累加,假设micro-batch的大小是 \(b\), 实际的有效的batch大小是 \(m \cdot b\) 。
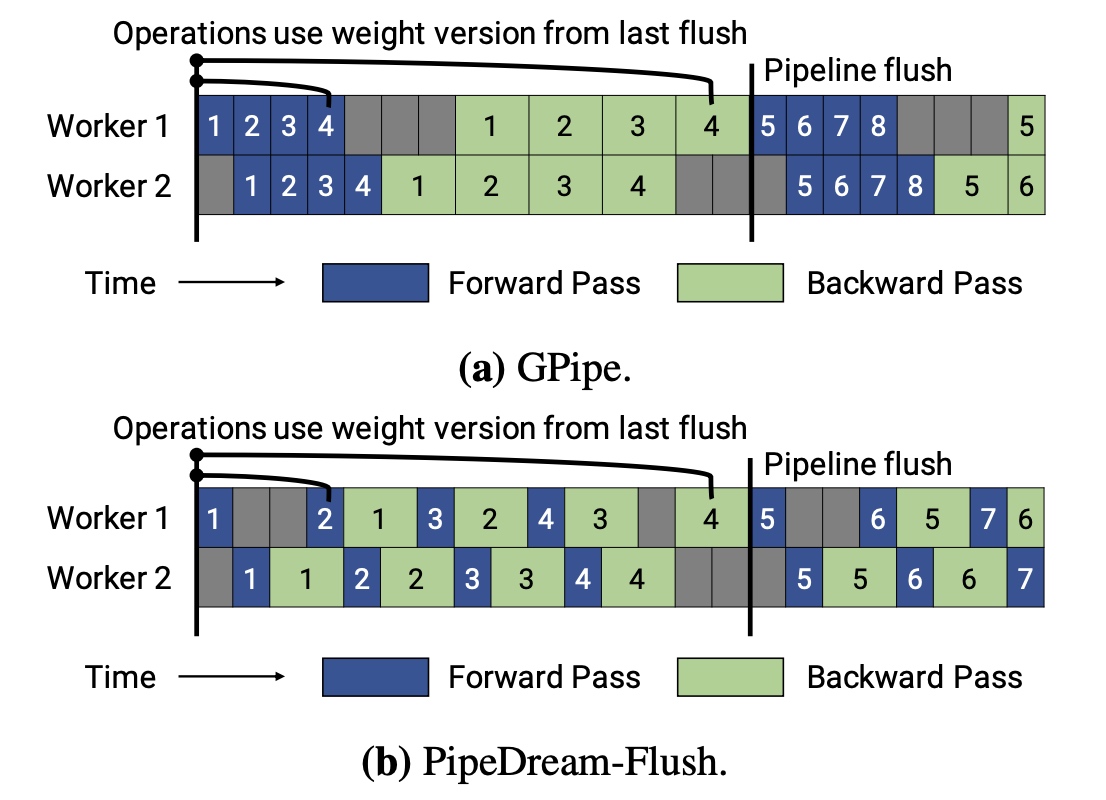
\(Weight\ updates\ with\ Flushes\
(PipeDream\
Flush)\):这个是另外一种节省显存的pipeline调度方法,比2BW的显存更少,这个方法复用了1F1B调度的思路,但不同的是只保存了一个版本的weight,PipeDream-Flush可以看成是1F1B方法在GPipe中的应用。
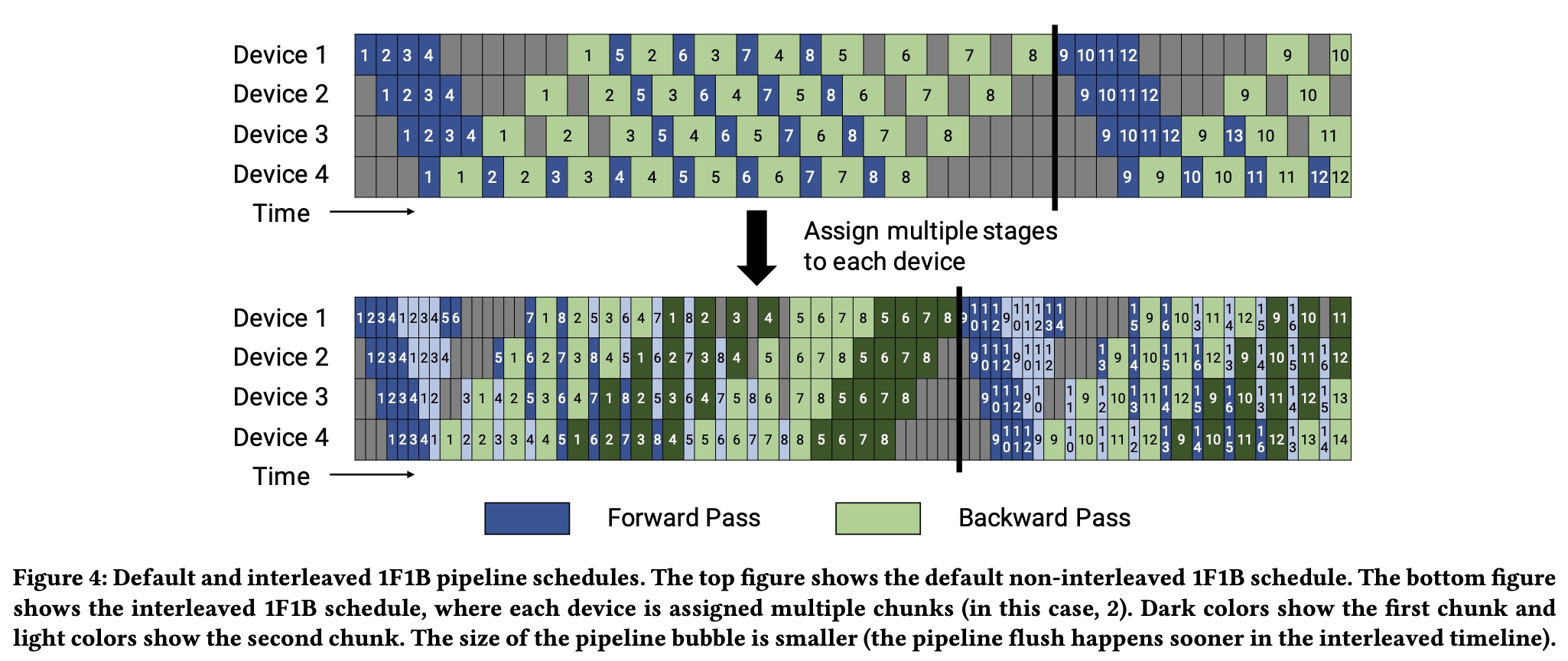
3. Megatron Schedule with Interleaved Stages
在之前pipeline基础上很容易看到Megatron
pipeline的思路,在Megatron中pipeline并行采用了Interleaved Schedule的方式。之前做pipeline
stage切分时,对于每个device会被分到连续的layer(比如device1分到layer1-4,device2分到layer5-8),一组连续的layer被称为一个model chunk,每个device只会处理一个stage;为了减少pipeline
bubble气泡的大小,在Interleaved Schedule方法中,改为每个device会被分到两组model chunk的内容,(比如device1分到layer1/2和layer9/10,
device2分到layer3/4和layer11/12),这样每个device会来处理多个stage。
如下图,深色表示第一个model chunk的内容,浅色表示第二个model chunk的内容。每个device分到 \(v\) 个stage,对于每个microbatch的前向和后向时间分别为 \(t_f/v\) 和 \(t_b/v\) 。对应的bubble时间减少为 \(t_{pb}^{int}=\frac{(p-1) \cdot (t_f + t_b)}{v}\) 。
\[\begin{gather*} Bubble\ time\ fraction\ (pipeline\ bubble\ size) = \frac{t_{pb}^{int}}{t_{id}} = \frac{1}{v} \cdot \frac{p-1}{m} \end{gather*}\]
4. 参考
- Efficient Large-Scale Language Model Training on GPU ClustersUsing Megatron-LM
- GPipe: Easy Scaling with Micro-Batch Pipeline Parallelism
- Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models
- torchgpipe: On-the-fly Pipeline Parallelism for Training Giant Models
- PipeDream: Generalized Pipeline Parallelism for DNN Training
- PipeDream-2BW: Memory-Efficient Pipeline-Parallel DNN Training
- FlexFlow: Beyond Data and Model Parallelism for Deep Neural Networks
- Efficient Algorithms for Device Placement of DNN Graph Operators
- Mini-batch gradient descent
- Differences Between Epoch, Batch, and Mini-batch