GPT-3(Language Models are Few-Shot Learners)论文阅读
1. 论文阅读
1.1 背景介绍
GPT-2中虽然已经可以通过预训练和下游任务finetune实现不错的效果,但仍存在问题:下游任务finetune仍然需要成千上万的标注样本。为此提出了GPT-3,GPT-3也是一个自回归语言模型,但参数量更大,具有175B参数量,是GPT-2的117倍,大力出奇迹。
GPT-1、GPT-2、GPT-3模型参数量对比如下:
| 名称 | 参数量 | 时间 | 补充 |
|---|---|---|---|
| GPT-1 | 110M | 2018年 | GPT-1论文阅读 |
| GPT-2 | 1.5B | 2019年 | GPT-2论文阅读 |
| GPT-3 | 175B | 2020年 |
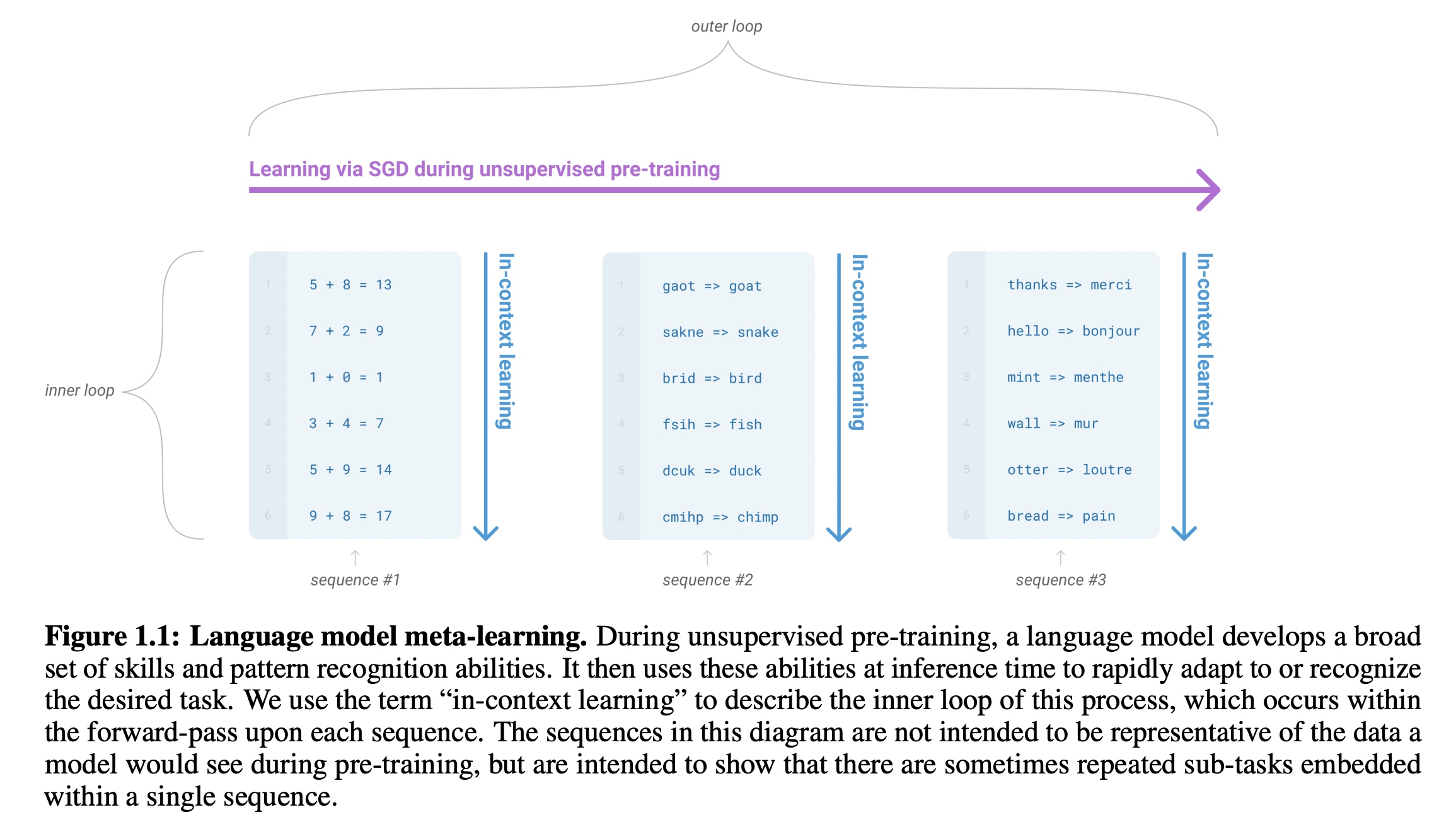
在GPT-3中使用了跟GPT-2一样的方式,这里称为in-context learning(也就是Prompt,
通过加上了上下文信息来做任务的自动区分),模型在无监督学习下会有识别不同类型范式(pattern)的能力。类似下图中有三种不同类别的sequence范式,样本中识别完类别后相当于进行该范式的循环学习。
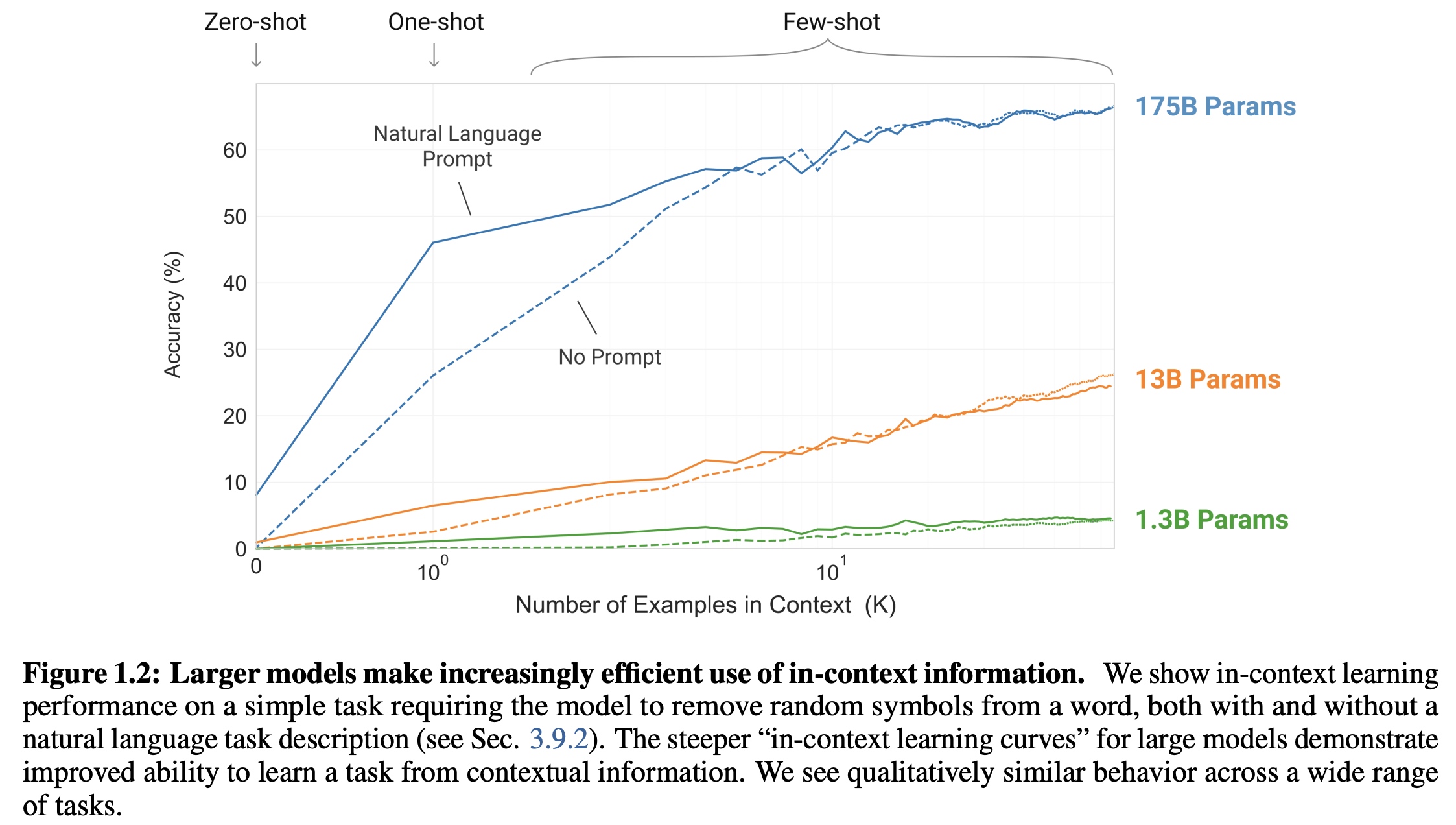
测试发现当模型越大对于测试的zero-shot/one-shot/few-shot相关的效果越好。
1.2 GPT-3评测特点
GPT-3在评测过程中没有进行finetune,也就是没有相关的gradient梯度更新。只用到了zero-shot、one-shot、few-shot分别对应在推理时的上下文中增加的prompt样本个数。

1.3 模型结构
整体结构跟GPT-2一样,但不同的是才用了类似Sparse Transformer的sparse attention,
如下图,测试了不同超参的GPT-3模型。
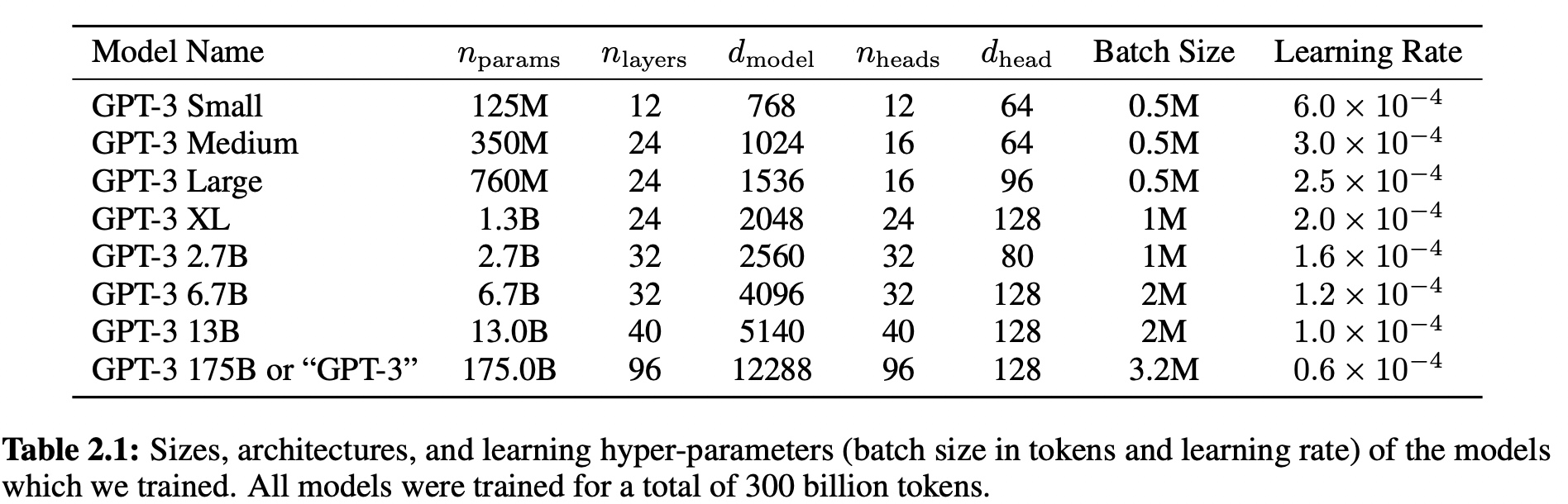
1.4 训练数据
在GPT-3中采用了3步提升训练数据质量: 1. 采用过滤过的CommonCrawl数据 2. 在文档粒度进行了去重操作 3. 增加了更多的高质量数据语料
具体训练数据如下图: 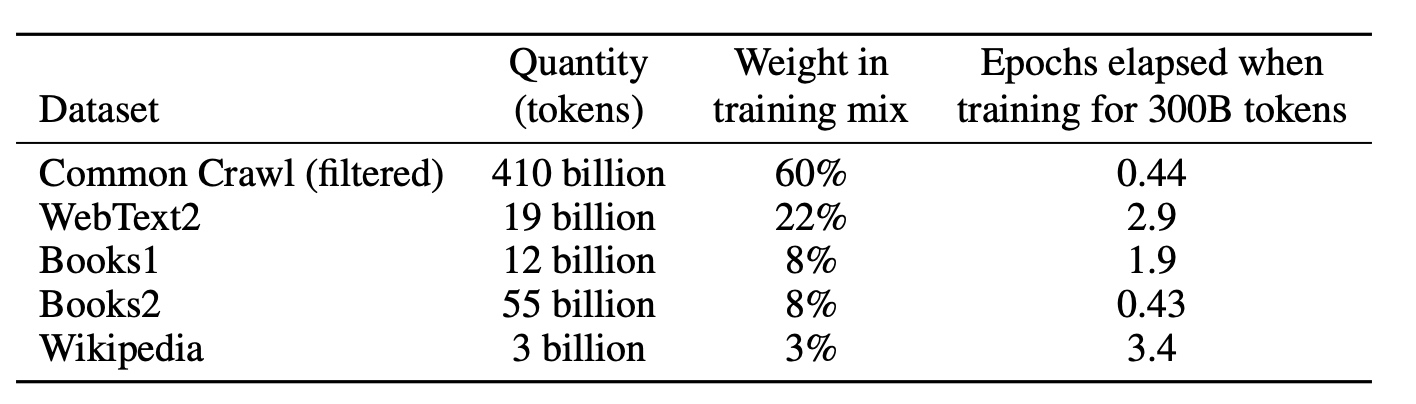
1.5 结果
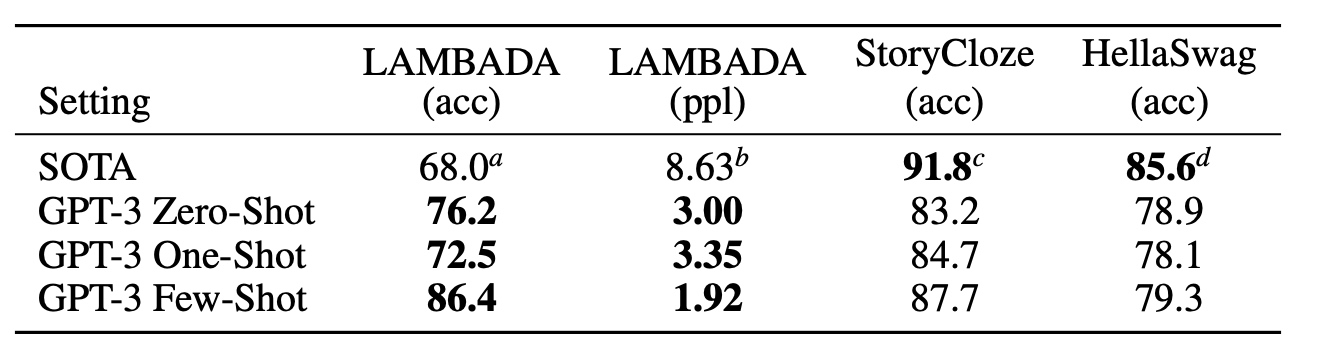
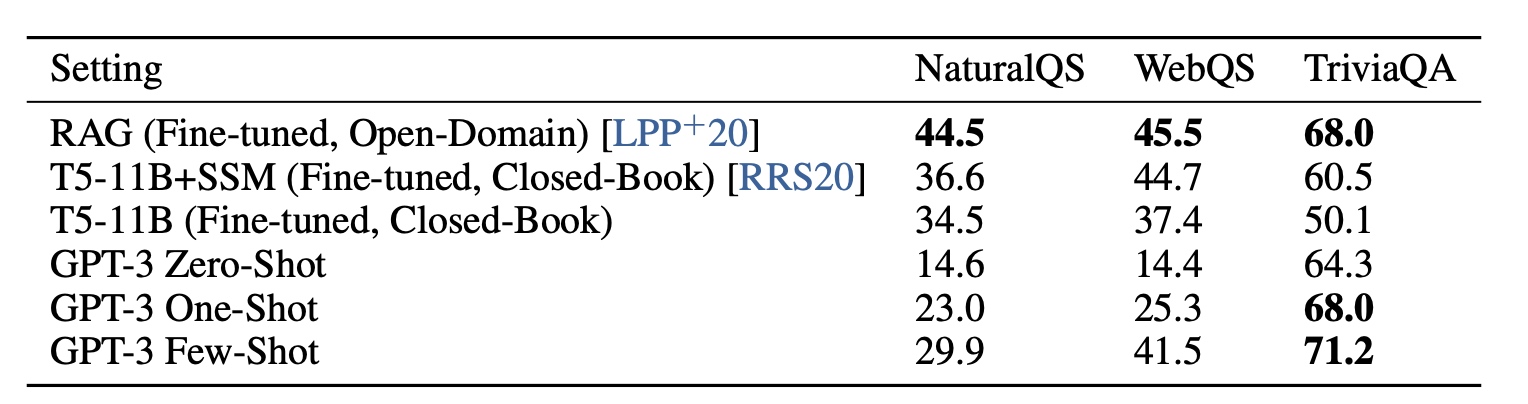
没有finetune情况下在多个任务上效果还不错, 如下: