GPT-1(Improving Language Understanding by Generative Pre-Training)论文阅读
1. 论文阅读
1.1 背景介绍
在GPT(Generative pre-trained transformer)大火的今天回去重读了GPT在18年的开山之作【Improving Language Understanding by Generative Pre-Training】。在面对NLP众多种类任务(自然语言推理/问答/文档分类)时有大量无标注语料,相对而言,有标注的语料非常少。
为此论文提出一个新的训练思路: 先基于海量无标注语料进行通用的生成式预训练,然后针对下游任务使用有标注的数据进行finetune。这算是一个两阶段的半监督训练方法, 先后融合了无监督的预训练和有监督的finetune训练。
1.2 模型框架
- 无监督的生成预训练
对于语言模型训练来说,给定一组token序列(也就是对应一句话)U,
U={u1, u2, u3, ..., un}, 目标最大化下一个token的最大似然,k是上下文的窗口大小。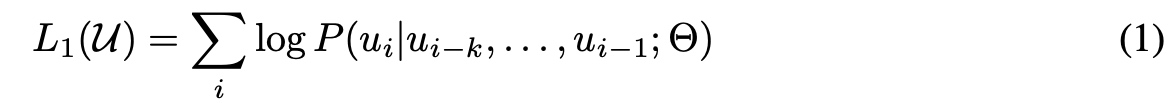
在实现时使用多层transformer
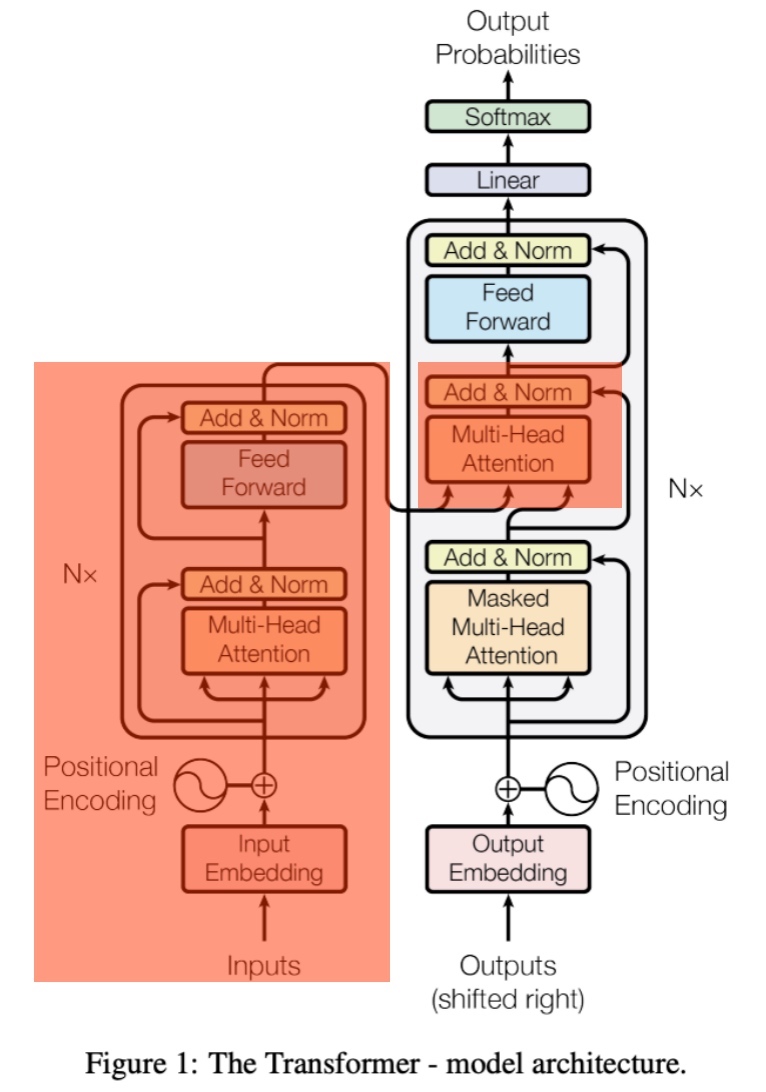
decoder来实现,给定一组token的输入,通过多头自回归注意力机制实现下一个token的预测。需要注意的是对于生成来说,跟原始transformer论文不同的是,这里只用到了transformer decoder,并在decoder中去掉了前一encoder的输入的multi-head attention部分,
如下图:
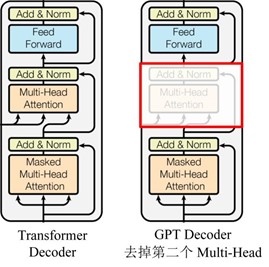
GPT Transformer结构跟Attention Is All You Need论文中的Transformer结构不同,去除之前的输入的Transformer Block和Multi-Head的块(红色部分)。
对应论文中的公式如下: 
- 有监督的finetune训练
给定一个有标注的数据集C,其中token序列
(x1, x2, ..., xm)对应的label是y,对于transformer的输出h,乘上一个参数矩阵W。学习目标是最大化对应的最大似然。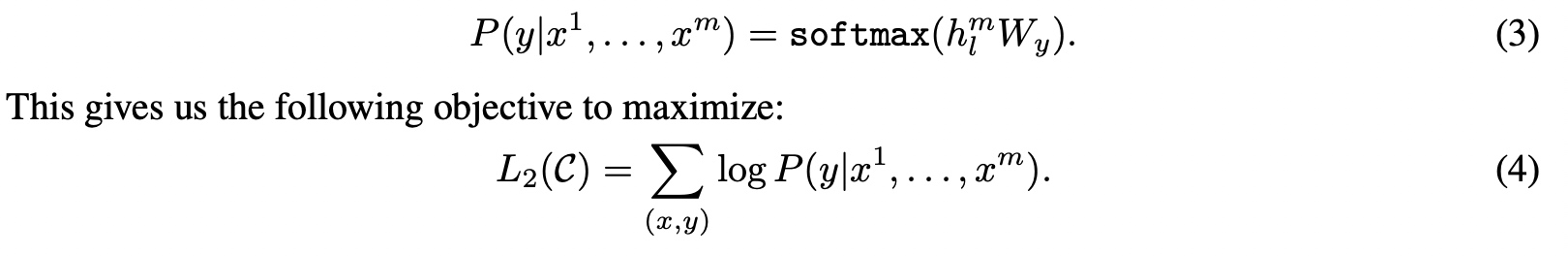
需要注意的是finetune中也要考虑模型的通用性,所以增加了下个辅助学习目标(Auxiliary Learning Objective),这里对应的是预训练模型的L1(C),即公式(1)。最终目标如下:

finetune过程中不是对所有参数进行更新,只对参数矩阵W和token embedding层进行更新。
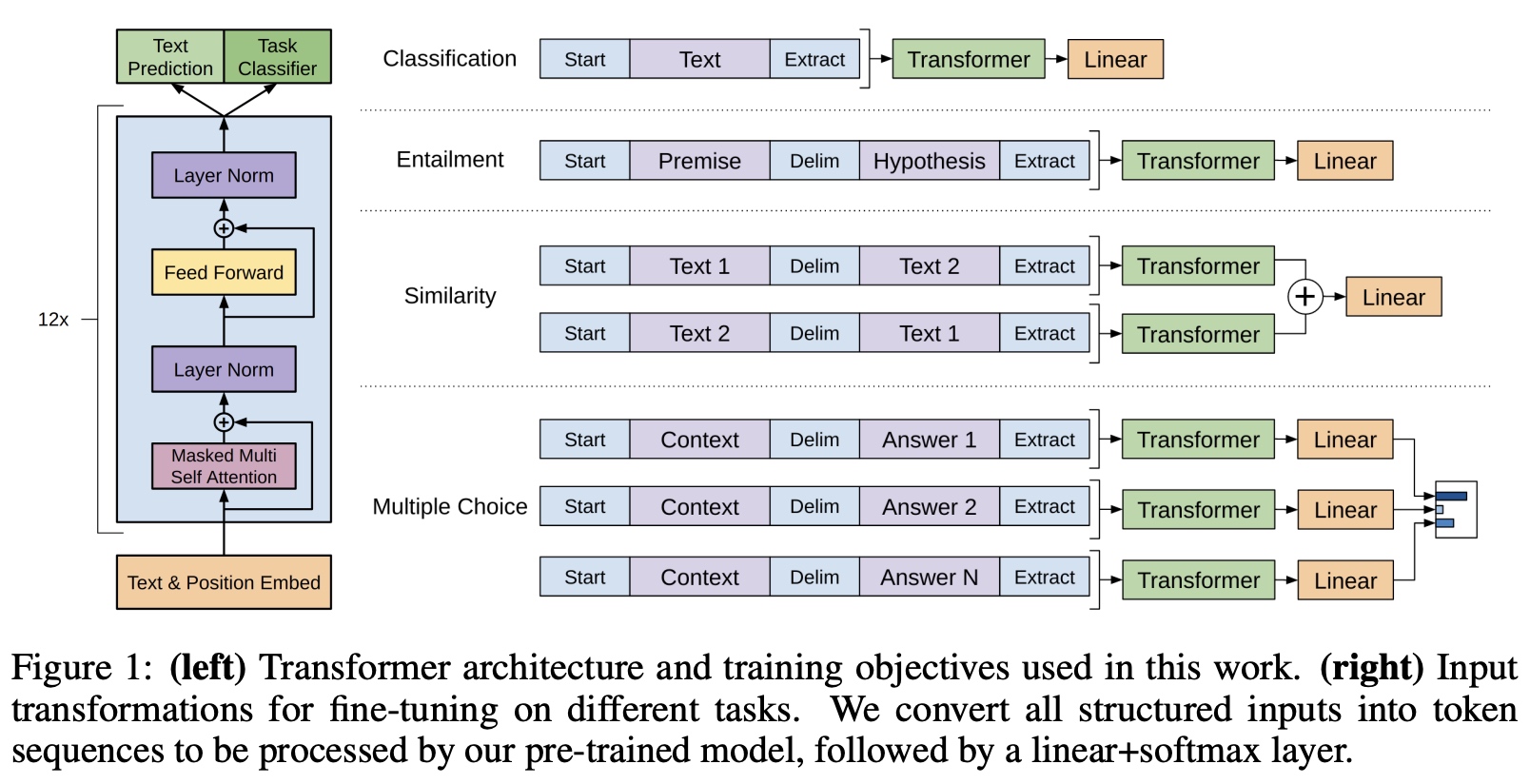
下游任务的输入格式统一 下游任务的输入格式不统一的话,对于不同NLP下游任务进行迁移学习时通常都要在网络中增加新的任务相关的模块,为了达到transformer网络格式针对不同NLP下游任务不变的目标,这里对不同的NLP下游任务输入格式进行了统一处理。例如:
- 文本推理任务:拼接了前提(premise)和假设(hypothesis),中间通过分隔符(Delimiter)隔开
- 语义相似度:两个句子没有固定的前后关系,这里分别按可能的前后顺序进行了拼接,然后最终输出在linear操作前进行了element-wise操作。
最终整体架构如下: