伯克利团队关于未来AI系统发展展望
本文主要根据A Berkeley View of Systems Challenges for AI进行了汇总,以及一些材料上的收集,论文中对未来AI系统以及研究的方向做了非常广泛的讨论。
AI发展的趋势介绍
关键任务(Mission-critical) AI
Mission-critical的含义就是在AI在生活中起到的任务越来越重要,例如自动驾驶、机器人辅助医疗、智能家居等,这些AI的应用非常关键以至于可以影响到人的生死。AI在不断变化的环境中进行部署,必须不断的适应周围环境并学习新的知识。比如自动驾驶需要在处理之前没有遇到过的危险场景中,观察学习其他车辆如何行动从而恰当的处理。另外,关键任务AI也要能处理各种噪音数据以及恶意的攻击。挑战: 不断地与周围动态环境进行互动学习,从而做出及时、鲁棒、安全的决策。
个性化(Personalized) AI
基于用户的个性化决策要考虑到用户自己的习惯与偏好,例如虚拟助理的语音可以模仿用户的口音,自动驾驶可以学习用户的驾驶习惯等。这样的个性化应用需要收集到大量敏感的用户信息,这些信息的滥用可能会造成用户的经济以及精神上的伤害。
挑战: 设计AI系统必须支持个性化的应用,但是这些个性化应用不能损害用户的利益,不能泄露用户的隐私。
跨组织的AI
许多公司在利用第三方的数据去提升他们自己的AI服务能力,例如医院之间的数据共享可以更好的组织传染病的爆发、金融机构之间的数据共享可以更好的进行反欺诈检测。这种应用的扩展使得从一家公司进行数据收集、处理,变成了一个公司使用多方的数据资源来进行决策。
挑战: 设计AI系统需要支持多源数据的训练,这些数据都来自不同的公司或者组织,并在训练过程中保证各家原始数据的机密性,在保证数据机密性的基础上甚至可以提供AI的能力给它的竞争对手。
AI的需求超越了摩尔定律
海量数据的存储和处理是近些年AI系统成功的关键,由于下列两个原因使得后续的数据处理能力很难跟上数据扩张的速度。 * 数据增长是指数级的。IoE设备在2018年采集的数据大小是400ZB,是2015年的50倍,到2025年,需要有3到4个数量级的增长才能处理人类的基因组数据,需要要求接下来的每年计算能力都至少要翻倍。 * 硬件的发展到了瓶颈。需要10年DRAMs和磁盘大小才能翻倍,需要20年CPU的性能才能翻倍。
挑战: 发展领域(domain-specific)的架构和软件系统去满足后摩尔时代性能要求,例如定制的人工智能芯片、高效处理的数据的边缘云计算(edge-cloud)以及数据的采集与抽样方法的发展。
未来研究的机遇
这里根据上述说的4种发展趋势,总结出来了9种未来可能的研究的机遇(R1-R9),这9点研究方向分属于三个主题(动态环境下的AI学习、安全AI、AI专属架构),如下图所示
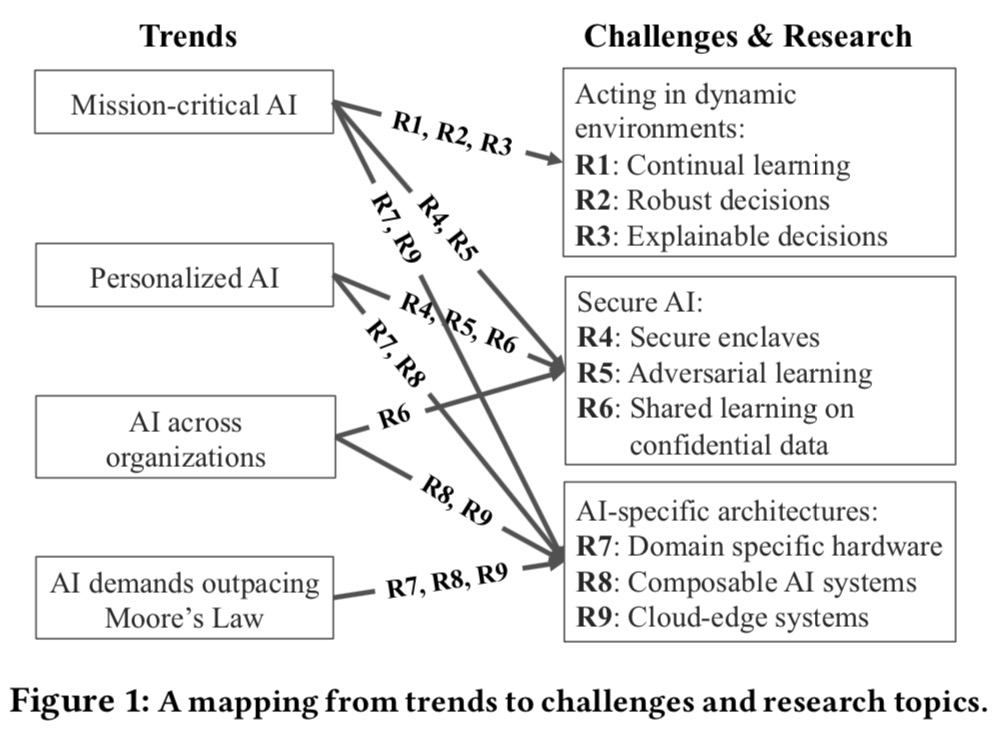
R1 持续学习
持续学习的一种方法是在线学习(Online Learning),通过在线学习对模型可以进行天级别、小时级别的更新,传统的在线学习不能很好的处理控制问题, 对环境变化的适应能力不够,特别是在关键任务上处理的不好。为了处理更加通用的问题一个方向是采用增强学习(Reinforcement Learning)来进行处理,RL算法的本质是学习一个策略函数(也叫Policy),这个Policy可以将观察到的东西作为输入数据,然后映射到一组行为上作为Policy的输出内容,例如自动驾驶中观察到小汽车摄像头中的内容以及用户的请求作为输入, 然后产生了汽车减速或者给用户展现广告的策略结果输出。尽管RL算法现在取的了一些成绩,但后续还会有更大的发展,目前很多系统的设计还没有涉及RL。我们需要建造一个增强学习的新的系统,系统可以通过传感器获取环境的变化,然后每条会执行上百万次的模拟以优化模型结构,目前已有的HPC和分布式系统都达不到这样的要求。另外一点需要做的仿真(Simulated Reality),因为现实环境中的交互或者环境触发是非常低频的,一个靠谱策略的学习需要经过大量的实验,这时要求我们去构建一种仿真的系统来持续的模拟现实环境,并给出每条执行策略预期的结果反馈。仿真的作业除了可以非常快的进行交互反馈,另外还可以规避交互过程中的可能的安全风险。再说下跟VR与AR的区别,VR主要是模拟虚拟的环境(如Minecraft游戏),AR主要是考虑虚拟与现实的一种结合。
总结: * 构建一个RL系统支持高效并行处理以及动态图处理,毫秒级延时,支持异构硬件 * 构建SR系统可以真实模拟现实世界,模拟现实中的不停变化,而且支持快速的交互
R2 决策的鲁棒性
在关键决策中,针对输入数据中的不确定性以及错误信息要具有高的鲁棒性,鲁棒性要处理的问题主要有两个,一个是如何应对噪音数据,以及负面的反馈;另外一个是在未知场景和负面输入的情况下如何进行决策。例如聊天机器人使用正常人对话的语料就可以训练的非常好,但一旦换成了Twitter的预料,聊天机器人的回答就非常负面了。另外在位置场景下,实际输入系统的数据的分布可能与之前训练数据的分布不符,这时系统会更倾向于采用保守的操作。例如自动驾驶在未知天气情况下,更倾向于采用缓行的方式进行运作。
总结: * 系统需要把产出的反馈结果与数据的源头进行关联,从而自动学习基于这些源头的带噪音的模型 * 设计新的API和语言,以满足决策的置信区间,特别是可以在未知场景下恰当地进行行动
R3 决策的可解释性
总结: * AI系统支持交互式的诊断分析,可以准确复现之前的结果,以此来确定输入中的哪些特征是对最终结果起到了决定性的作用。另外系统可以提供因果分析。
R4 安全飞地(Secure Enclaves)
飞地是一种人文地理概念,意指在某个地理区划境内有一块隶属于他地的区域。这里安全飞地主要是为了处理针对AI系统的攻击而提出的,所有运行在飞地内部的AI系统程序都会收到保护,使得它们不受飞地外部恶意代码的影响,类似于沙盒。Intel提供了一种名叫SGX(Software Guard Extensions)的技术来提供硬件上的运行环境的隔离。所有在SGX内部的代码在数据上进行计算的时候,飞地外部的其他角色(例如: 操作系统或者管理员)是没办法看到这些代码和数据的。类似的ARM提供了名叫TrustZone的硬件飞地技术。当然,在飞地内部,如果代码是不健壮的,还是有可能泄露飞地内部的隐私数据,为了应对这种情况,有研究者尝试类似沙盒的静态或者动态验证工具以防止加密数据的泄露。有了安全飞地以后,如何将应用代码拆分,然后最小化安全计算的范围是接下来另外一个研究课题,拆分的主要原因有两点,一个是很多函数功能在安全飞地内部并不支持,例如GPU或者程序本身不支持运行在安全飞地,另外一个原因云厂商提供的这种安全措施花费会更贵。
总结:
* 要使用安全飞地需要对代码进行拆解,最小化安全运行代码的范围,
还要保证运行在安全飞地内部的代码不会泄露隐私数据。
R5 对抗学习
目前AI系统面临的攻击有两种: 一种是闪避攻击(evasion attacks), 闪避攻击主要发生在预测阶段,通过构建特殊的预测数据来对系统产生干扰。例如在自动驾驶场景中,人眼中看到的是一个STOP的标识,但是放入预测以后确显示是一个缓行的标识。目前并没有什么好的办法来识别这种攻击,不过有研究在分析这种构建特殊预测数据的成因以及避免方法。
另外一种是恶意数据攻击(data poisoning attacks), 恶意数据攻击主要发生在训练阶段,攻击数据中包含错误标注的样本数据,系统学习到的模型就会有偏差。同样也有研究在探索如何检测这种恶意数据攻击,以及如何使得训练是有弹性的,可以避免这种情况的发生。
总结: * AI系统在训练和预测的时候需要非常鲁棒地处理对抗性的数据,可能的措施有设置新的模型和网络结构,定位异常数据源,定位以后通过重做决策来更新执行策略。
R6 基于保密数据的共享学习
现在很多公司自己都各自保存了自己收集的数据,希望更多的公司提供第三方的数据服务,在不泄露隐私数据的风险下可以互相从中受益,其实谈的就是一个合作与竞争的关系。采用共享学习的方式来进行这种合作,之前提过的安全飞地是可能的一种实现方式,但由于本身存在的支持范围的问题很难实施。这里又介绍了一种MPC(secure multi-party computation)的方法,这种方法允许有n个组织,每个组织都有一份隐私的数据源,可以在不泄露各自隐私数据的基础上来实现基于这些数据源的函数计算。MPC针对小型的计算非常高效,但针对复杂的模型训练代价很大。一个重要的研究方向是如何切分训练数据,区分为本地训练和MPC训练两种情况。
除了在隐私数据上进行模型训练,在模型预测服务中也容易泄露隐私数据,这时会采用差分隐私(differential privacy)的方式来避免,这是在统计数据库方面流行的做法。差分隐私方法为每次查询增加了噪音以防止隐私的泄露,其中的一个核心概念是隐私预算(privacy budget),限制了隐私保护下的查询数量。差分隐私方面有三个研究方向, 第一个是基于模型本身的统计特性,使用差分隐私技术处理复杂模型训练和推理;第二个是构建一个易用的差分隐私系统,使得应用可以方便简单地接入差分隐私技术;第三个是在持续学习中数据隐私是有时效性的,我们要让差分隐私系统设置时间窗口,去保护最新的未失效的隐私数据。
最后,我们还要提供激励措施去鼓励各个组织和企业去共享自己的数据,共享数据的企业会获得比不共享数据的企业更多的收益。
总结: * 在训练和预测中在不泄露隐私数据的前提下,可以用到多源的数据 * 提供激励措施鼓励企业或者组织共享数据
R7 领域定制硬件
总结: * 设计领域的硬件架构去提升AI应用的性能,例如FPGA/TPU/XPU等 * 使得软件系统可以充分利用到硬件架构的升级去提供服务
R8 组件化的AI系统
总结: * AI系统和API需要允许模型组合, 支持灵活地构建模型,例如TensorEditor就是这方面的尝试 * 采用API的方式去动态简化AI应用的构建过程
R9 跨越云服务与边缘设备的系统
当今很多AI应用是部署在云端的,例如语音识别系统。预计后续跨越终端与云服务的AI应用会越来越多,依据一方面是例如推荐系统现在会把越来越多的功能下放到了终端上,以此提高应用本身的安全保护、隐私保护、低延迟等,另一方面越来越多的应用开始使用云服务上强大的计算资源去做模型本身的优化。跨越云服务与终端的系统面临了下面一些挑战: * 终端与云服务提供的能力差距会不断增大,例如手机终端的电源以及空间大小会有更严格的限制 * 终端上会有越来越多的异构硬件,部署环境非常复杂 * 终端上的软件与硬件的升级速度远低于云服务的数据中心 * 存储容量的扩张速度在减慢,但数据的产出速度还是非常快的,导致可能没有足够的空间去存储数据
文中也提出了几种方法来解决: * 通过软件结构的升级以及编译技术针对不同的硬件设备对代码进行重新编译(XLA干的就是这个事情),然后通过API的方式对外提供服务。 * 另外一种方式是将AI系统进行拆分,在终端上运行准确度不那么高的小模型预测(考虑模型压缩也算一部分),而把计算密集型的模型训练部署在云端。这种组合的方式可以有效降低延时,同时精度也不会有明显损失。 * 为了解决数据量巨大的情况,一种研究方向是利用抽样等方式来减少数据量,也在特征和模型选择上有一定的应用。
总结: * 利用终端设备去降低响应延时、提高安全性、实现只能的数据保留技术 * 利用云服务资源去共享数据与模型给终端设备,在云端训练复杂的模型结构, 做出高质量的决策