Transformer推理加速方法-KV缓存(KV Cache)
1. 使用KV缓存(KV Cache)
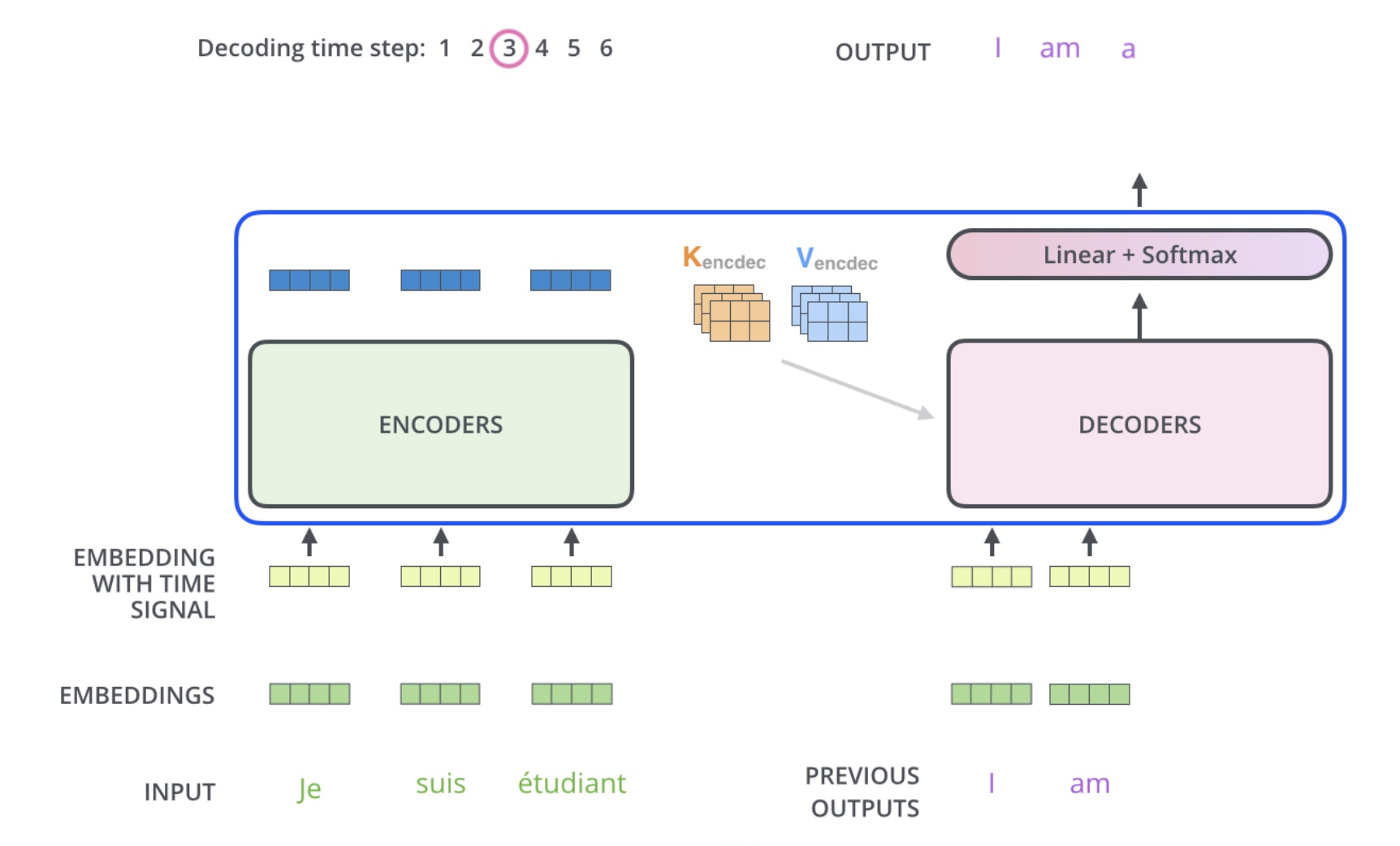
在推理进程中与训练不同,推理进行时上下文输入Encoder后计算出来的 \(K和V\) 是固定不变的,对于这里的 \(K和V\)
可以进行缓存后续复用;在Decoder中推理过程中,同样可以缓存计算出来的
\(K和V\)
减少重复计算,这里注意在输入是am计算时,输入仍需要前面I的输入。
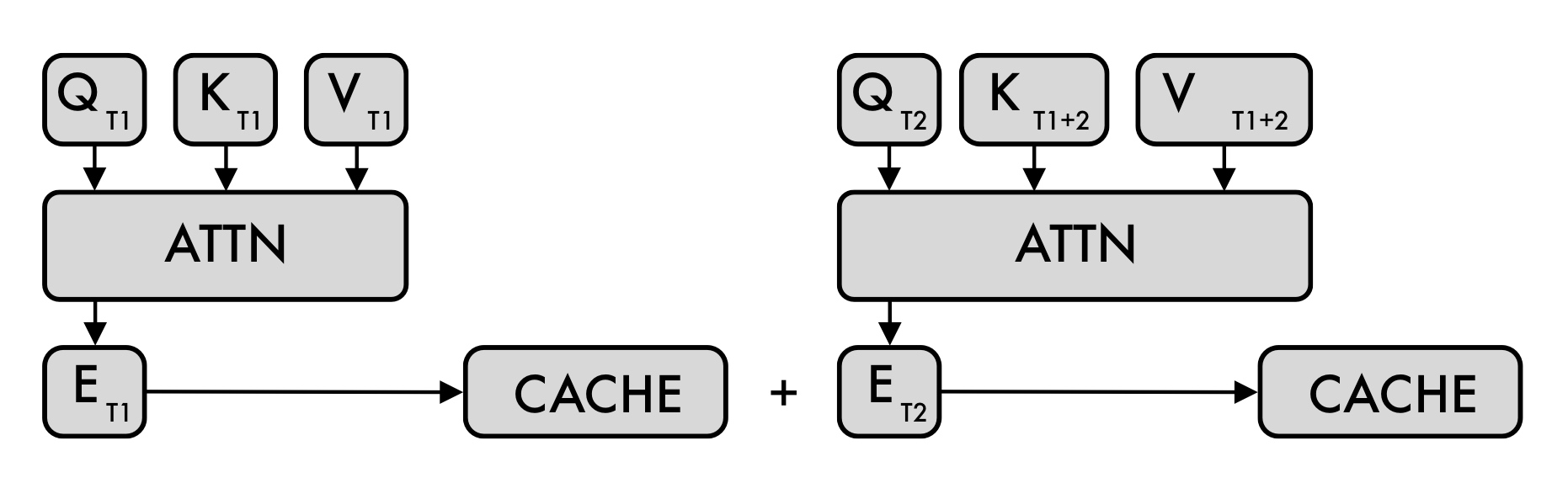
如下图:左边ATTN是Encoder,在T1时刻计算出来对应的
\(K和V\)
并进行缓存,后续推理都不用再计算了;右边ATTN是Decoder,T2时刻通过输入的一个词计算出来
\(Q_{T2}、K_{T2}、V_{T2}\),但计算Decoder过程中需要之前时刻T1的所用
\(K和V\)
向量。所以这里Decoder每次计算出来一组新的 \(K和V\)
向量都跟之前向量一起进行缓存,后续也可以重复复用。
实现的伪码如下: * 推理过程中只用取最后一个词做为输入
1 | q = q[-1:] |
- 当前输出只有一个值,在计算输出时把当前的output输出与之前输出cat到一起做为cache
1 | output = torch.cat([cache, output], dim=0) |
- attention的调用如下,每次除了当前时刻的KV值,还加上之前的cache输出
1 | output_t0 = attention(q_t0, k_t0, v_t0) |
- attention中的实现如下:
1 | self.attn_head = nn.MultiheadAttention(256, 8) |