详解大模型微调方法Prompt Tuning(内附实现代码)
Prompt Tuning是现在大模型微调方法中的一种常用方法,本文通过解读5篇论文来了解Prompt Tuning方法演进的过程。分别是Prefix-Tuning、P-Tuning v1、Parameter-Efficient Prompt Tuning、P-Tuning v2。
1. Prefix-Tuning:Optimizing Continuous Prompts for Generation
Finetuning之前是使用大模型进行下游任务重训的方法,但由于大模型参数量过大,Finetuning需要大量的数据,以及更多的算力去更新学习参数,不够实用。在2021年提出的prefix-tuning算法,并在自然语言生成任务(NLG, Nature Language Generation)上做了验证。这里注意区分下另一个NLP的概念,在NLP中还一类任务叫自然语言理解(NLU, Nature Language Understanding)。
在Prompt思想的启发下,在Prefix-Tuning中提出了给每一个input输入增加一个连续的任务相关的embedding向量(continuous task-specific vectors)来进行训练。
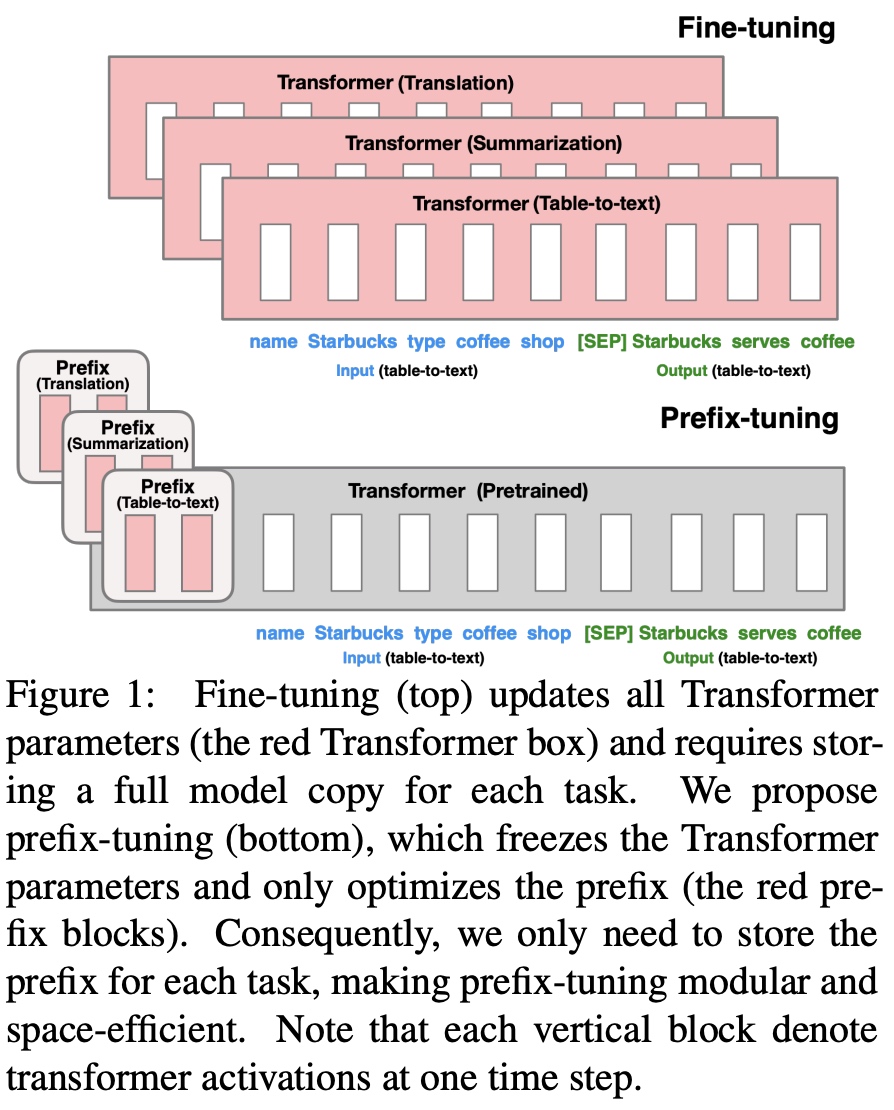
这里的连续(continuous)是相对于人工定义的文本prompt
token的离散(discrete)来说的,例如一个人工定义的prompt
token数组是['The', 'movie', 'is', '[MASK]'],把其中的token
The替换成一个embedding向量做为输入的话,其中embedding就是连续的(continuous)表达方式。在下游任务重训的时候固定原有的大模型所有参数,只用重训跟下游任务相关的前缀向量(prefix
embedding)即可。
对于自回归的LM模型(例如GPT-2)来说,会在原有prompt之前增加prefix(z = [PREFIX; x; y]);对于encoder+decoder的LM模型(例如BART)来说,会分别在encoder和decoder的输入前加上prefix(z = [PREFIX; x; PREFIX'; y],)。如下图所示,P_idx表示加的前缀序列,
h对应的是可学习的参数,
用Pθ=[h1, h2, h3, ...]表示可学习参数矩阵。
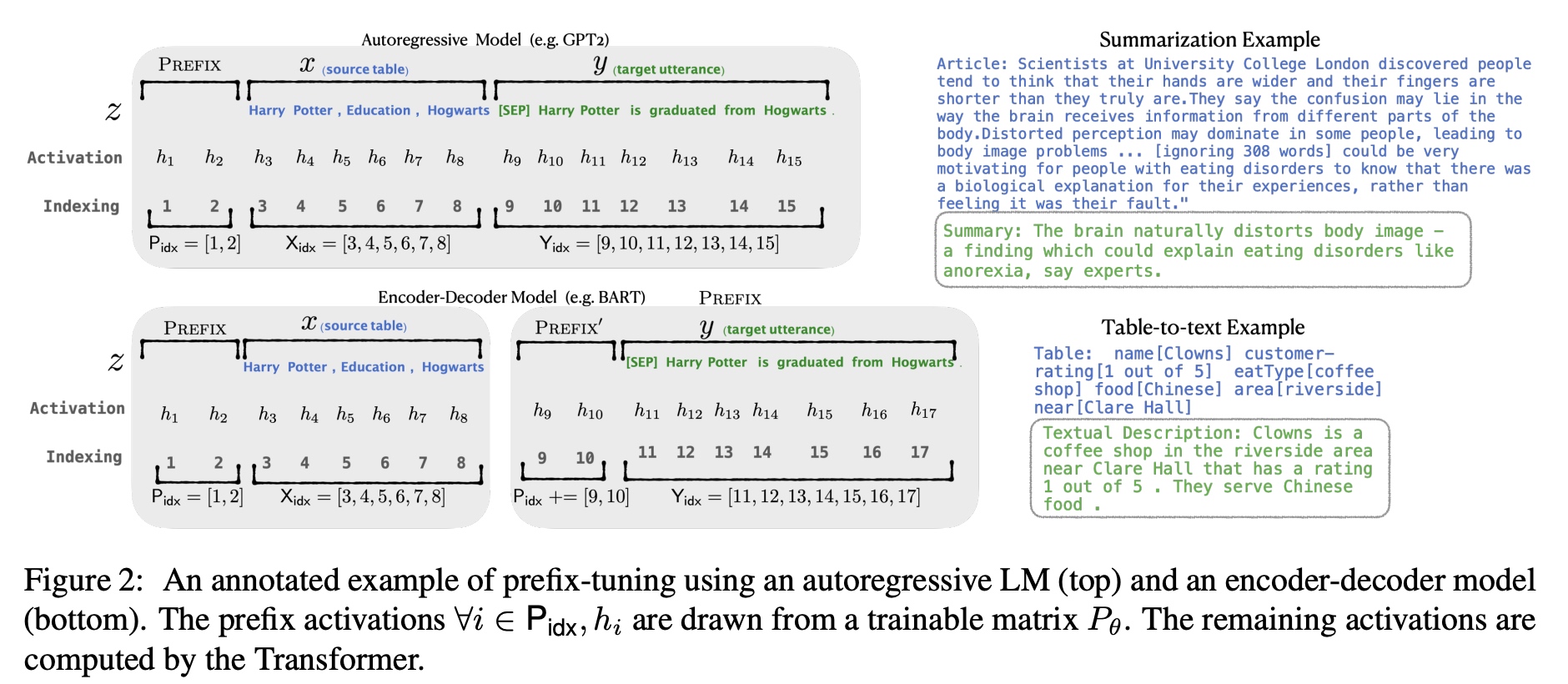
直接学习参数效果不好,所以使用MLP网络对Pθ进行了reparameter修正,即Pθ[i,:] = MLP(Pθ'[i,:]),重训完只用保存prefix的Pθ相关参数。
huggingface peft关于prefix-tuning的核心代码实现在PrefixEncoder
1 | class PrefixEncoder(torch.nn.Module): |
2. P-Tuning v1:GPT Understands, Too
P-Tuning这个词在这篇文中被第一次提出,为了跟后续P-Tuning v2区分,这里加了个v1。本论文主要是为了解决GPT大模型在自然语言理解任务(NLU, Nature Language Understanding 重训效果不好的问题。在P-Tuning方法中会在连续向量空间中自动搜索合适的prompt,来增强重训练的效果。
对于之前存在的离散prompt搜索方法(discrete prompt search)来说, 比如AUTOPROMPT、LPAQA,
其中的Prompt Generator通过接受离散的反馈来选择合适的prompt。
对于Prompt Generator来说,给定一个词库V和语言模型M,
P_i表示在prompt模版T中第i个token,会用词库V中的词来填充模版并并生成embedding向量,
例如:
[e_template(The), e_template(capital), e_template(of), e_input(Britain), e_template(is), e_output([Mask])], 其中template表示模版的,input表示输入,ouput表示输出。
而在P-Tuning中通过Prompt Encoder来实现prompt的生成,跟之前的区别在于这里使用了伪prompt和反向传播来对encoder进行更新。在embedding的输入上有所不同,模版中的prompt
token
embedding向量都是从Prompt Encoder生成出来的,没有对应词库中具体的词。
例如:
{h0, ..., hi, e_input(Britain), hi+1, ..., hm, e([MASK])}
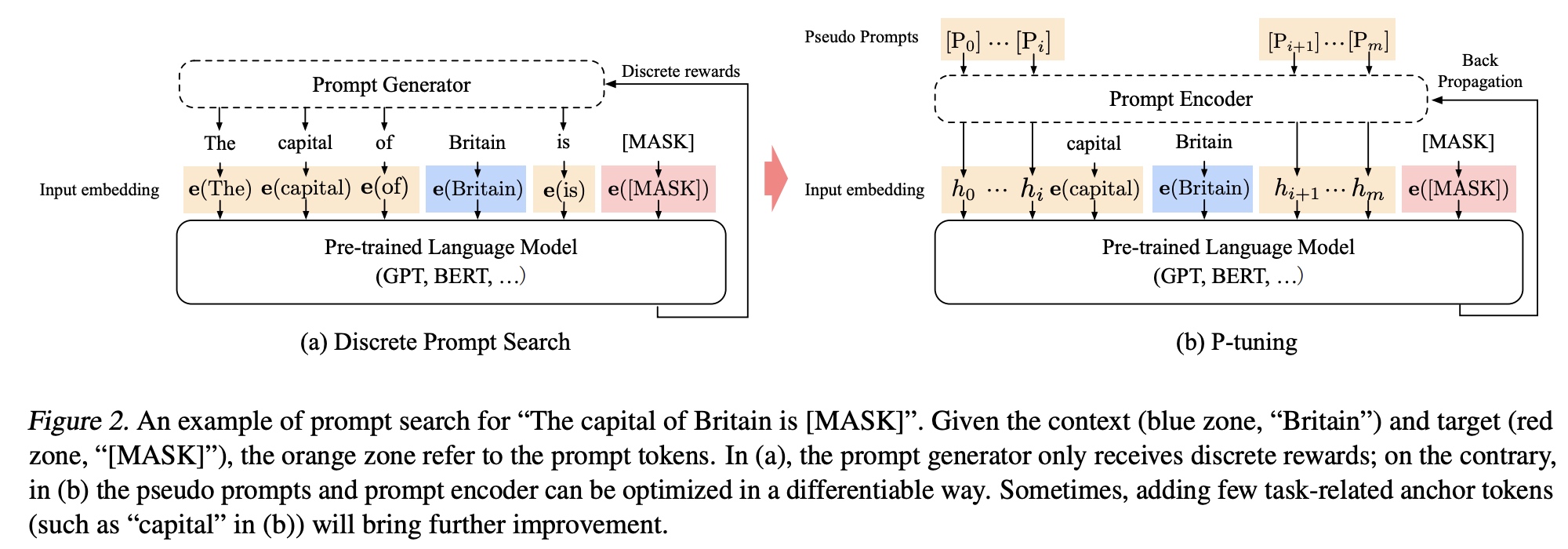
在网络结构上使用embedding层加上基于双层LSTM和relu激活的MLP来实现。训练过程中使用LSTM,但在推理过程中可以把LSTM给去掉。
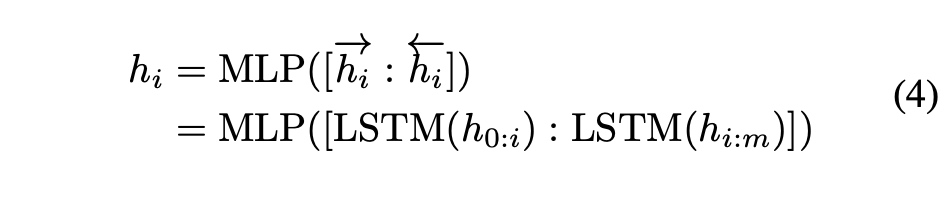
最终在效果上实现了bert等大模型重训的提升。 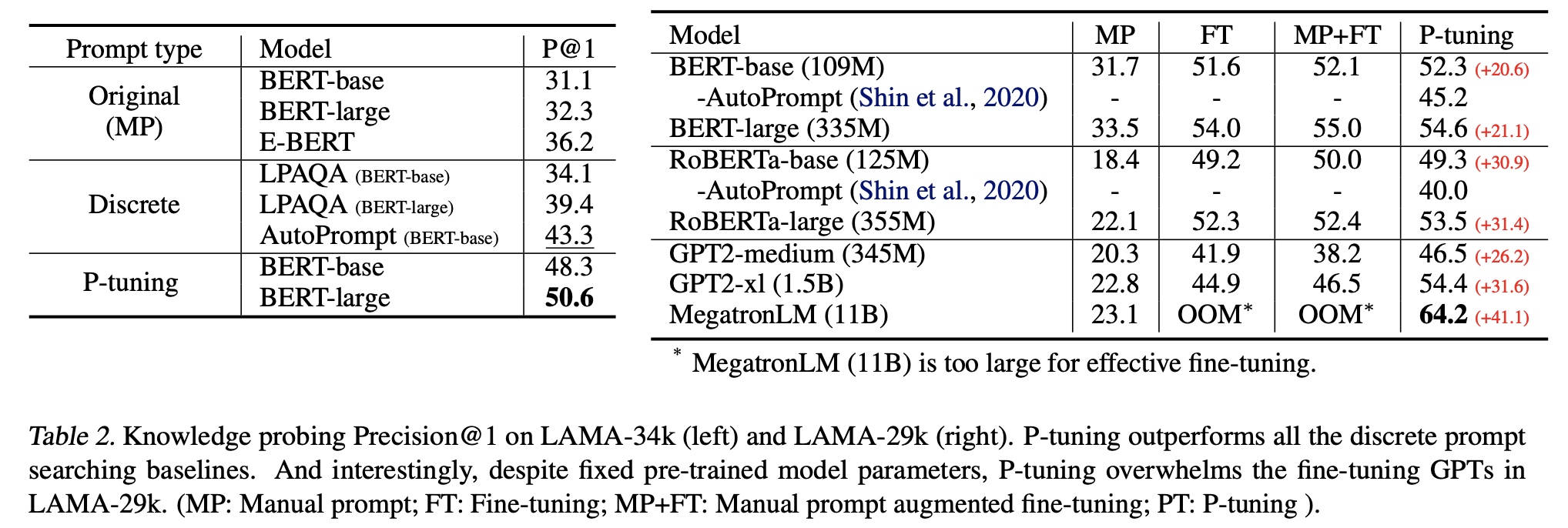
huggingface peft关于p-tuning的核心代码实现在PromptEncoder
1 | class PromptEncoder(torch.nn.Module): |
3. Parameter-Efficient Prompt Tuning
本篇论文可以看成是prefix-tuning的简化版,一方面文中实验证明了使用自动生成的soft prompt方法进行tuning的效果跟model tuning差不多,同时超过了人工设计的prompt。
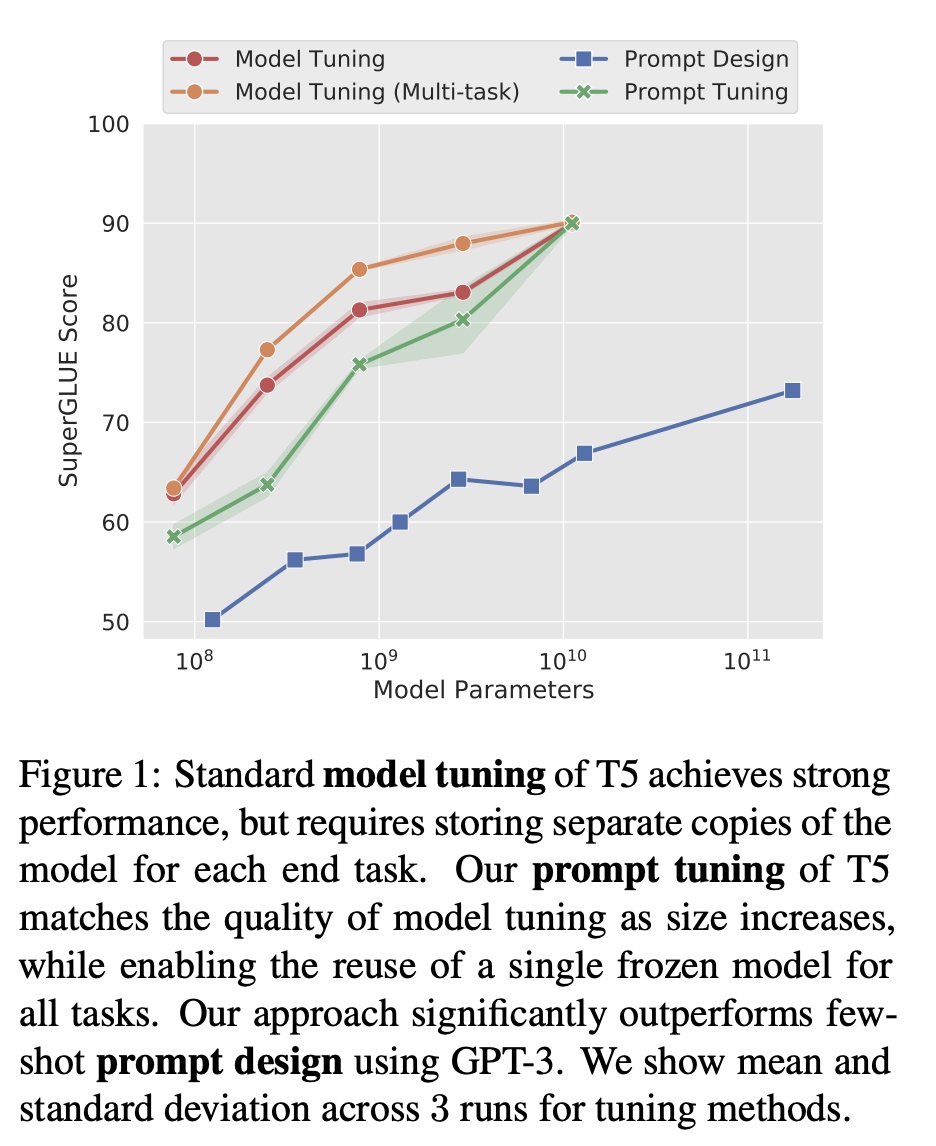
另一方面,文中对model tuning和prompt tuning做了如下图的对比,prompt
tuning可以大幅节省参数量。对于T5的XXL的model来说,全量的model
tuning每个下游任务需要11B的参数量,用prompt
tuning只需要20480个参数。需要注意跟prefix-tuning不同点:这里的prompt-tuning没有包含中间层的prefix,也没有对下游任务的输出网络进行修改。在prefix-tuning中使用了MLP进行prefix的reparameter

huggingface peft关于prompt-tuning的核心代码实现在PromptEmbedding
1 | class PromptEmbedding(torch.nn.Module): |
4. P-Tuning v2
在模型参数量小于10B的训练中,prompt
tuning效果还是不及FT(fine-tuning),
P-Tuning v2支持330M~10B规模的多任务tuning。P-Tuning v2可以看成是Deep Prompt
Tuning在NLU领域的实现,而Deep Prompt Tuning用于问答任务的训练。
跟之前区别主要有以下几点: 1.
对于NLU任务没有使用像MLP的Reparameterization。 1.
在模型的每一层上都加上了layer
prompt,不同任务可以共享相同的网络参数,支持多任务学习 2.
在分类头的verbalizer中使用了一个随机初始化的linear head 3.
Prompt长度对于简单分类任务小于20,对于像序列标注这样的复杂任务需要100左右
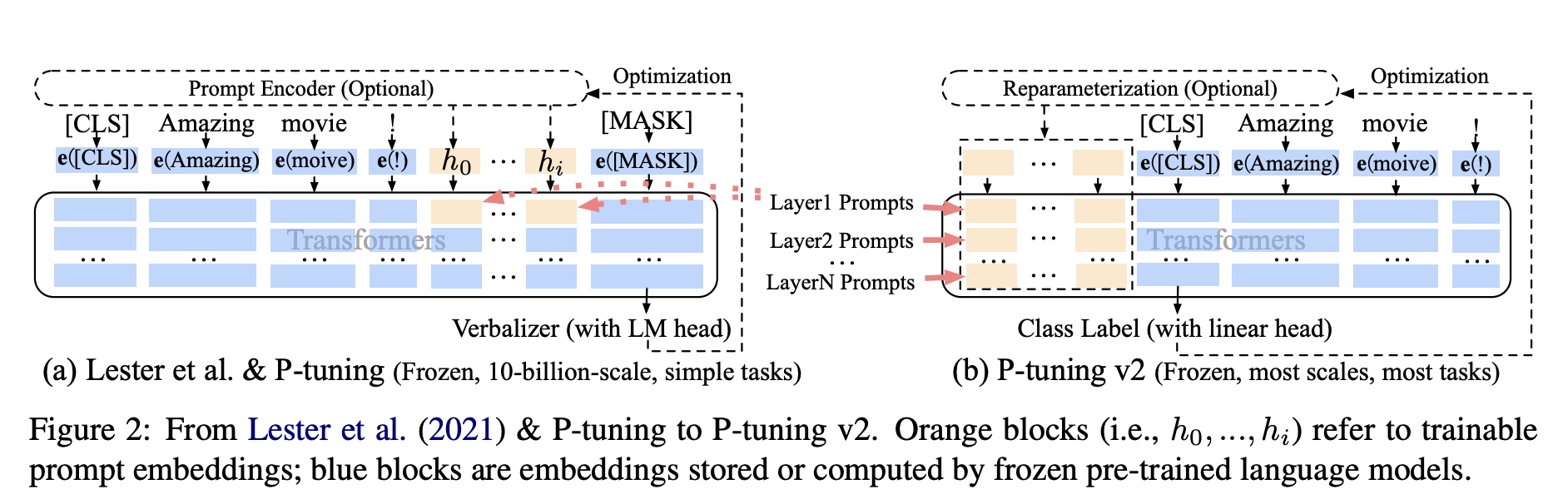
以bert分类任务为例,P-Tuning v2相关的核心代码实现在BertPrefixForTokenClassification
在实现的时候有一个get_prompt方法,通过这个函数提前生成各层的prompt的prefix向量
1 | class BertPrefixForTokenClassification(BertPreTrainedModel): |
然后在forward中通过self.bert方法中的past_key_values方法把prefix向量传入,在前向计算时会把传入的prefix向量进行拼接。
1 | class BertPrefixForTokenClassification(BertPreTrainedModel): |
对于past_key_values可参考huggingface
transformer中的实现【BertSelfAttention】。在forward中如果设置了past_key_value会通过torch.cat和layer的参数进行拼接。
1 | class BertSelfAttention(nn.Module): |
5. 参考
- Prefix-Tuning: Optimizing Continuous Prompts for Generation
- GPT Understands, Too
- The Power of Scale for Parameter-Efficient Prompt Tuning
- DPTDR: Deep Prompt Tuning for Dense Passage Retrieval
- P-Tuning: Prompt Tuning Can Be Comparable to Fine-tuning Across Scales and Tasks
- https://github.com/huggingface/peft/tree/main
- Dense Passage Retrieval for Open-Domain Question Answering
- https://github.com/facebookresearch/DPR