Clipper低延迟在线预测系统设计
简介
在生产环境部署模型预测的时候,在负载较高的情况下也对实时性、准确性、鲁棒性有很高的要求。现有很多的机器学习框架和系统都是针对模型训练而不是预测。本文中Clipper是一个通用的低延迟预测服务系统,通过模块化的架构来简化模型预测的部署。
Clipper1 2系统是一个分层的架构, 通过分层简化了预测服务栈, 并实现了预测服务的三个目标:低延迟、高吞吐、提高准确度。整体被分为了两层, 第一个是模型抽象层(model abstraction layer), 第二个是模型选择层(model selection layer)。抽象层提供了统一的API来屏蔽ML框架和模型的差异,实现模型对应用的透明;模型选择层在模型抽象层之上,动态选择模型进行预测并融合不同模型预测结果,从而提供更加准确和鲁棒的模型预测服务。
为了实现低延迟和高吞吐,Clipper中采用了非常多优化手段。在抽象层中,Clipper针对不同模型的预测进行了缓存,并针对请求延迟的情况进行自适应调整batch大小,最大化提升请求吞吐量。在模型选择层,为了提高预测的精度,Clipper采用了bandit方法,对不同模型预测的结果进行了集成,评估模型预测的不确定性;在降低延迟方面,也采用了优化落后者(straggle3 mitigation)方法,预测过程中不等待最慢的模型的返回值。作者对Clipper用Rust进行了实现4,添加了多机器学习框架的支持, 包括Spark MLlib, Scikit-Learn, Caffe, TensorFlow, HTK等。
系统架构详细说明
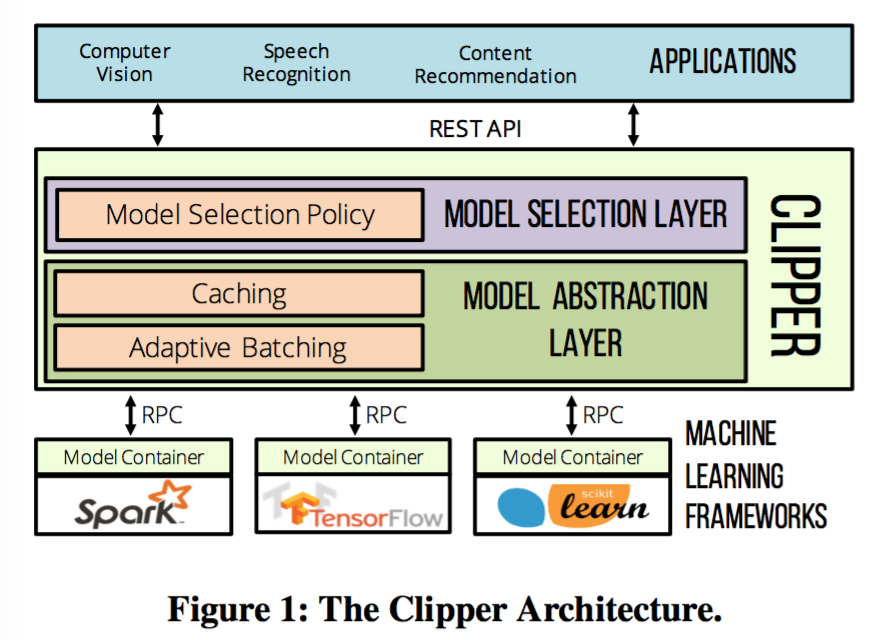
Clipper架构被分为了模型选择层和模型抽象层,抽象层负责提供统一的预测接口,保证资源的隔离,针对批处理的(batch oriented)机器学习框架优化预测请求的负载。选择层负责将预测请求分发给不同的模型,基于反馈来组合预测结果,以此提高预测的准确度、评估不确定性、提供鲁棒的预测服务。
系统中预测请求先从请求方通过Clipper提供的REST或者RPC API发送过来,Clipper收到请求以后选择层根据请求的类型和最近的反馈,将请求通过模型抽象层分发给具体的一个或者多个模型进行预测操作。模型抽象层在将请求分配给自适应批计算队列(adaptive batching queue)以前,会先检查请求在预测缓存区中是否存在。Adaptive-batching-queue保存了针对不同机器学习框架和模型进行调整过的预测请求,然后请求会通过RPC发送给保存具体的模型的容器进行处理。这里为了方便处理,我们把模型容器部署到不同的Docker容器中。预测完成以后,结果会按照请求的反向顺序先发送给抽象层,然后是模型选择层。模型选择层会根据收到的多个不同模型预测的结果生成最终的预测结果以及估计置信度,最后把结果返回给请求的终端。终端请求方也会统计预测的效果,并将收集到这些信息通过RPC/REST请求发送给模型选择层。模型选择层会根据收到的反馈信息来对预测进行调整。接下来来介绍模型抽象层和模型选择层。
模型抽象层(Model Abstraction Layer)
模型抽象层中第一部分是预测缓存,可以针对高频query请求提供部分预先实体化机制(partial pre-materialization mechanism), 通过高效结合最近的请求和反馈结果来加速自适应模型选择技术(adaptive model selection)。第二部分是批处理模块, 请求被聚合成可以动态调整大小的mini-batch,以此来提供吞吐量。mini-batch一旦被创建,就会通过RPC请求发送给模型容器进行预测。Clipper中的模型都是被部署到轻量级的容器里,通过RPC接口来与Clipper进行交互。轻量级的RPC系统可以减少基于容器架构的开销,简化跨语言的集成。下面分别讨论抽象层的几个部分。
缓存(Caching)
对于很多业务(例如内容推荐)来说,预测服务中存在某些热门query会被频繁请求。通过维护预测缓存,Clipper可以针对这些热门query直接返回结果,不用再次进行实际的模型预测。通过缓存可以消除一些冗余的模型预测开销,进而减少系统延迟和负载。除此以外,缓存在模型选择时也起到了重要的作用。为了模型选择更加智能,Clipper需要对预测结果和应用的反馈来进行join操作。反馈的结果会在预测以后很快返回,这样非热门或者单一的query也能从缓存模块中收益。例如,对于一个针对四种模型(随机森林,LR,Scikit-Learn中线性SVM,Spark中线性SVM)的融合,Clipper缓存提升反馈处理的吞吐量大约1.6倍,从观测到的每秒6K提升到了每秒11K。
缓存实际上是对通用的预测函数进行了缓存,Predict(m: ModelId, x: X) -> y: Y,
输入一个模型id m 以及query
x,然后计算相关模型的预测输出
y。对外暴露了简单的非阻塞 request 和
fetch
两种API。当一个预测请求来临,request会在没有命中的情况下通知缓存进行预测计算以及返回一个布尔变量判断缓存中是否存在当前请求项。fetch
会检查缓存,当缓存中存在请求项直接返回值。
Clipper缓存中实行的是LRU更新策略(CLOCK缓存更新算法)。当缓存空间大小合适的话,频繁请求项都不会被替换,缓存对热门选项起到了一个部分预先实体化机制(partial pre-materialization mechanism)的作用。因为自适应模型选择是在cache模块的上游,预测过程中的变化也要考虑到模型选择模块不会让缓存项失效。
批量(Batching)
Clipper batching模块将实时的预测数据流转换为多个batch,用来最大化适配当前机器学习框架的负载开销;同时也会摊销RPC与系统的开销。batching提高了吞吐以及最大化利用了物理资源(例如GPU),但是延迟依旧很大,因为在返回单个预测结果之前,要等待batch中所有的请求项全部计算完成。我们通过显示指定延迟的服务等级(Service Level Objective, SLO)来增加延迟,以此来换取吞吐量的提升。通过用户指定延迟目标(latency objective),Clipper可以通过调整batch预测请求来最大化吞吐,同时也可以满足应用方的延迟需求。例如,有效的大batch可以在满足20ms 延迟目标(latency SLO)的基础上把预测请求的吞吐提高26倍(如图4中sklearn SVM).
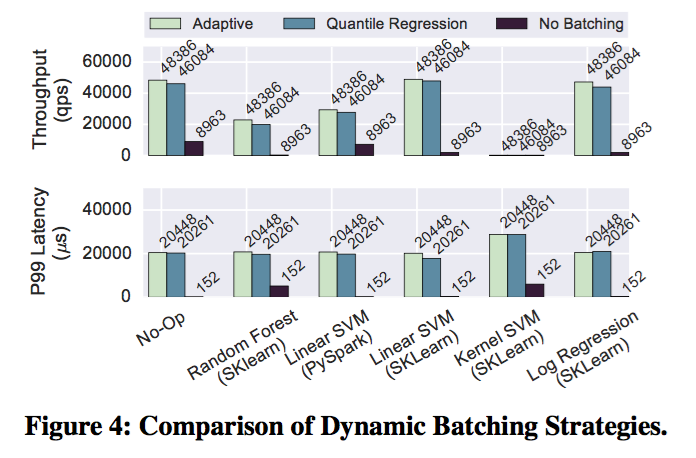
batching模块通过两种机制来提升吞吐。一种是baching摊销了RPC请求和内部框架的开销,例如把请求内容拷贝到GPU内存;其次,batching支持机器学习框架采用以后的数据并行的优化方式来对同时对batch中的请求进行处理(例如使用GPU或者BLAS加速)。模型选择层把请求分发给与模型容器对应的请求队列。每个模型容器都有它自己的自适应batch请求队列,通过一个线程来处理预测请求。模型预测模块从队列中以batch的方式来取数据,没个队列都设置有最大的batch容量。通过设置batch的最大容量,可以保证满足用户设置的延迟目标,避免最先到达队列的请求严重超时。
因为不同机器学习框架的实现不同, 以及模型选择的不同导致在模型吞吐和延迟的差异。在不同模型容器预测的过程中,给定一个指定大小的batch数据,数据预测的时间会产生波动。例如在图3中,线性SVM与带核函数的SVM在20ms 延迟目标下,最大batch大小的变动相差了有241倍。因为线性SVM的预测只用执行简单的向量乘法,而带核函数的SVM预测必须执行一系列复杂耗时的近邻计算。线性SVM的吞吐可以达到30000的qps,在同等SLO限制下,带核函数的SVM只能达到200qps。Clipper采用了一种自适应的最大batch大小调整的算法,以此来代替用户手动指定模型的batch大小。
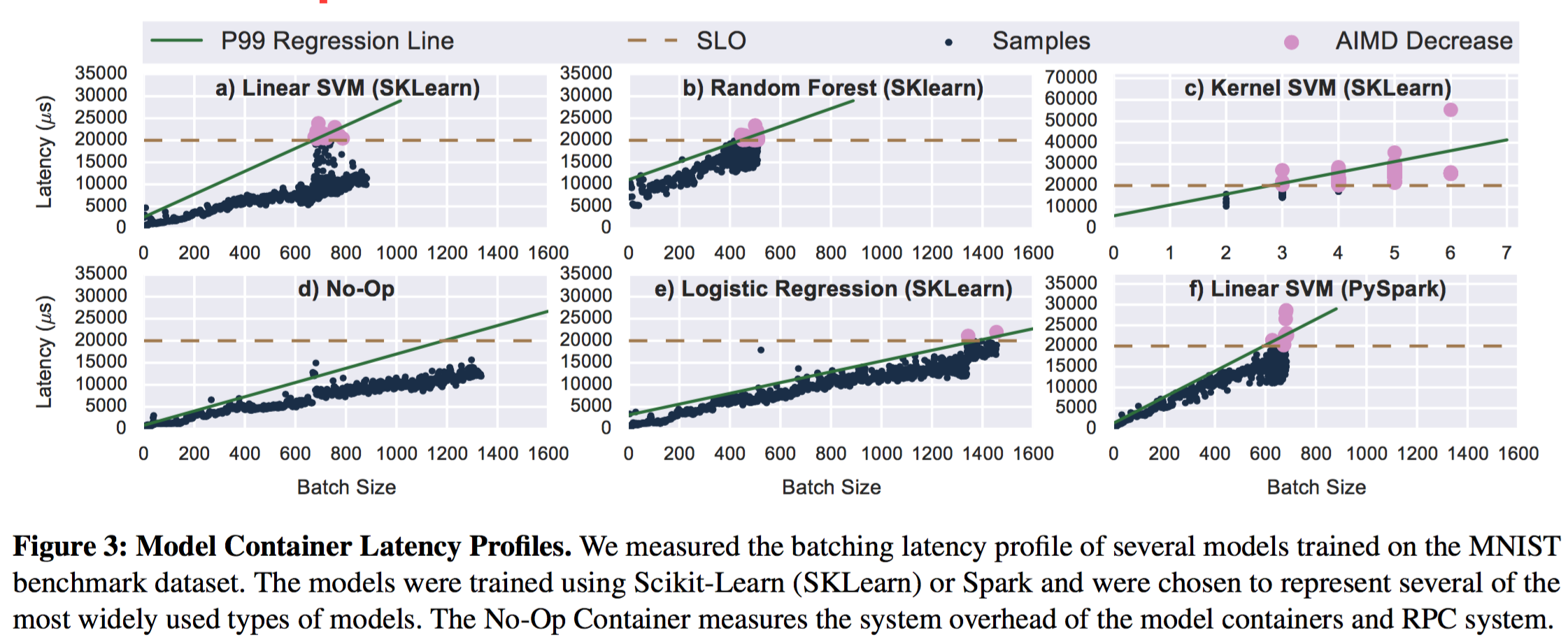
动态调整batch大小
这里采用了加法增加,倍数减少(additive-increase-multiplicative-decrease AIMD)的机制。在这种机制下,每次通过给batch大小增大一个指定的大小,直到处理batch的延迟超过SLO的上限;然后我们采用小的百分比的方式来做batch大小的回退,每次减少batch大小总量的10%。相比别的AIMD算法,这里我们采用一个小的回退常数,使得最优的size最终不会波动。图3中的结果得知一个batch大小与延迟之间有一个稳定的线性关系,因此我们也可以使用分位点回归(quantile regression5)来估计P99(99th-percentile)6延迟, 根据这个延迟来设置batch大小的上限。在图4中我们在Spark和sklearn上比较了两种方式,相比无缓存的情况,两种策略都可以得到性能的提升。在sklearn的线性SVM上达到了26倍吞吐量的提升。AIMD方法更加简单,以及在后续自适应过程中AIMD显的更加鲁棒去改变模型的吞吐容量(例如在Spark垃圾回收的间歇),因此Clipper中实现的时候采用了AIMD的方式。
延迟batching
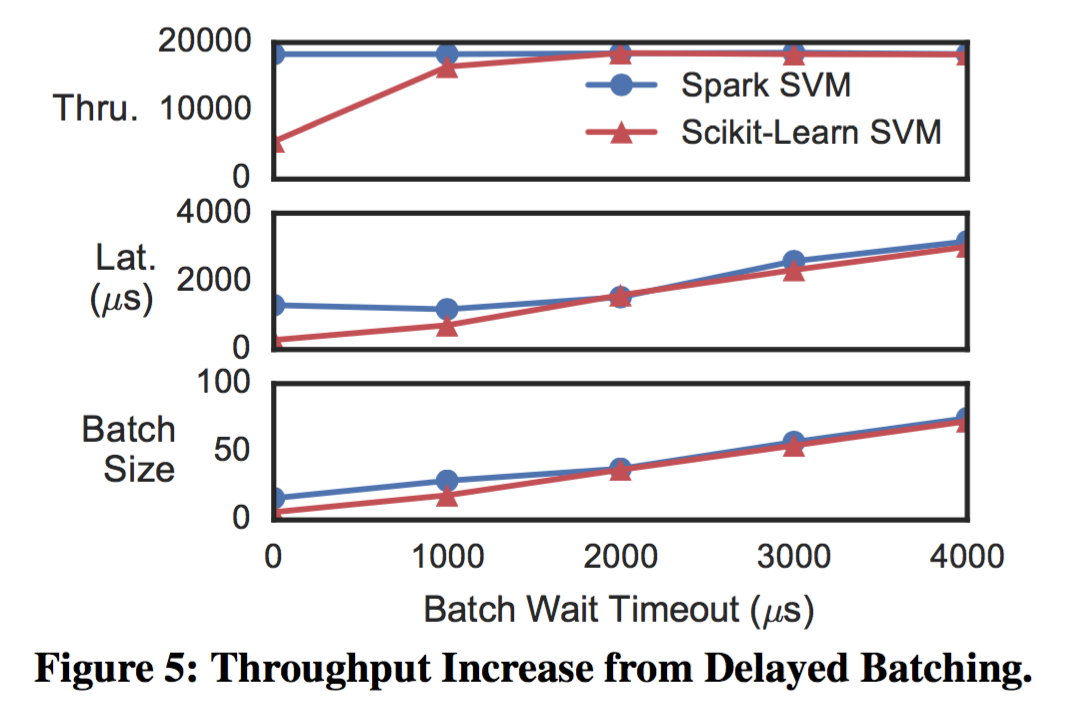
当一个batch从队列中读取预测样本数据打包要发送的时候,会存在batching队列中的样本条目少于一个batch的最大容量。对于某些模型来说,通过延迟打包等待更多样本数据到达,在请求突增的情况下可以显著提高系统的吞吐水平。与Nagle算法7的动机很像,效率的提升是从发送batch的固定消耗与提高batch大小的不固定消耗之间的比率来确定的。图5中我们比较了Spark与sklearn上SVM模型采用延迟打包对吞吐量提升效果。Spark SVM上吞吐没有增加,因为Spark在处理小batch大小的数据时已经非常高效。对比sklearn上针对数据处理有很高的固定开销,通过BLAS库来进行并行加速。最终,2ms的打包延迟可以提供3.3倍的吞吐提升同时低于10-20ms的延迟目标。
模型容器
模型容器封装了不同机器学习模型的差异性,提供统一的远程预测API接口。当往Clipper中添加新模型的时候只用实现一个如Listing 1中展示的标准模型预测接口。Clipper包含了各种语言的容器bindings,例如C++,Java,Python等。本文中容器实现只需要几行代码。

为了实现进程间的隔离,每个模型都被分开部署到一个独立的Docker容器中。可以保证性能,以防不成熟的机器学习框架对Clipper可用性上有影响。模型的相关信息比如模型参数会在容器初始化的时候传过去,在容器初始化以后容器本身就是无状态的了。对资源有要求的机器学习框架可以复制多分到不同的机器或者通过配置特殊硬件(比如GPU)来满足对资源的需求。
容器复制扩容
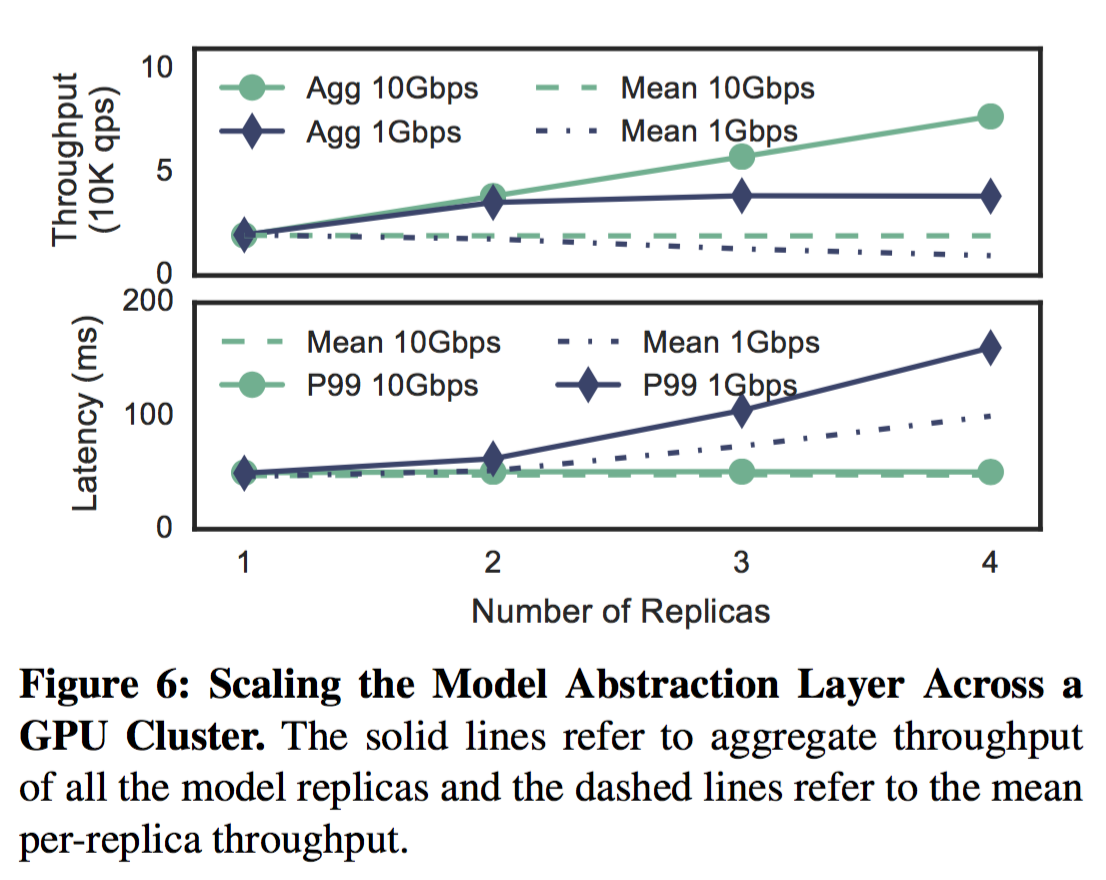
Clipper支持在本地或者集群上对模型容器进行复制,以此提升预测服务的吞吐以及利用额外的硬件进行加速。因为不同的副本的性能会有差异,特别是在集群上复制的时候,Clipper对不同的副本采用相互独立的自适应打包策略。在图6中我们描述了Clipper在集群上可以通过复制模型容器对吞吐量起到线性扩容的作用。一个4核,10Gbps以太网的GPU集群,使用本地GPU单个模型容器可以达到19500 qps,通过复制4份副本可以达到77000的qps,提升了3.95倍左右的吞吐量。本次实验是资源密集型,GPU的吞吐成为瓶颈而Clipper的RPC通信很容易使得GPU打满。然后当集群通过1Gbps的带宽链接,GPU的吞吐大于1Gbps,这时带宽则成为瓶颈。当机器学习应用开始处理大数据量的输入时,例如从手写字到图像处理,甚至是视频,带宽将会一直成为预测服务扩容的瓶颈。这就需要对网络策略进行另外的研究了。
模型选择层(Model Selection Layer)
模型选择层使用应用的反馈来动态选择已经部署的一个或者多个模型进行预测,并且对它们返回的结果进行融合,从而提供鲁棒的预测结果。模型选择层简化了新模型部署的过程,允许多模型同时部署以及依据反馈来自适应选择最好的模型或者模型组合。通过从前端应用的反馈中持续的学习,模型选择层会对预测失败的模型进行自动容错,无需人工干预。结合了多个模型的预测返回结果,模型选择层提升了预测的准确度与置信度。常用的模型选择技术可以用三个API来描述(select, combile, observe)。Listing 2中对这三个API进行了描述,它们掌控了整个模型选择层,并且允许用户使用自定义的模型选择技术。

图中定义了思仲重要接口。X与Y分别对应query类型与预测类型,状态类型S表示选择算法当前的状态。init函数返回一个选择策略状态的实例。我们隔离了选择策略状态,通过初始化函数来有效实例化选择策略的实例,从而实现细粒度的上下文模型选择(contextualized model selection)。select 和 combile 函数负责选择请求哪个模型以及如何组合预测的结果。另外 combile 函数还可以提供额外的预测信息,比如提供预测的执行度分数。最后 observe 函数负责根据前端应用返回的feedback信息来对状态S进行更新。
当前的Clipper实现中我们支持了两种通用的模型选择策略。这两种策略在计算开销与预测准确度之间做了权衡,单一模型选择策略利用了Exp3算法根据反馈优化select最好的模型,使得计算开销最小; 融合模型选择策略基于Exp4算法,可以自适应的combine预测的结果,从而提升预测的准确度、评估所有模型对每一条请求的计算开销。另外,用户也可以实现自己的模型选择策略。
单一模型选择策略(Single Model Selection Policy)
这里可以把模型选择问题转化为多臂老虎机(multi-armed bandit)问题, 在K个行为中(对应模型)进行选择,每个模型都对应一定的随机奖励(对应feedback)。需要在探索可能的action以及实施最好的action中间来做好权衡。在Exp3算法中针对\(k\)个部署的模型的每一个模型初始都设置一个权重\(s\_i = 1\), 然后随机选择一个模型\(i\)的概率是\(p\_i = \left.{s\_i} \middle/ {\sum^{k}\_{j=1}{s\_j}} \right.\)。对于每一个预测值\(\hat{y}\),Clipper求得一个损失值\(L(y, \hat(y)) \in [0, 1]\)。Exp3算法会根据选择的模型\(i\), 通过公式\(s\_i \gets s\_i exp(- \eta L(y, \hat(y)))\)来更新权重。常数\(\eta\)决定了Clipper针对最近反馈的响应速度。
模型融合选择策略
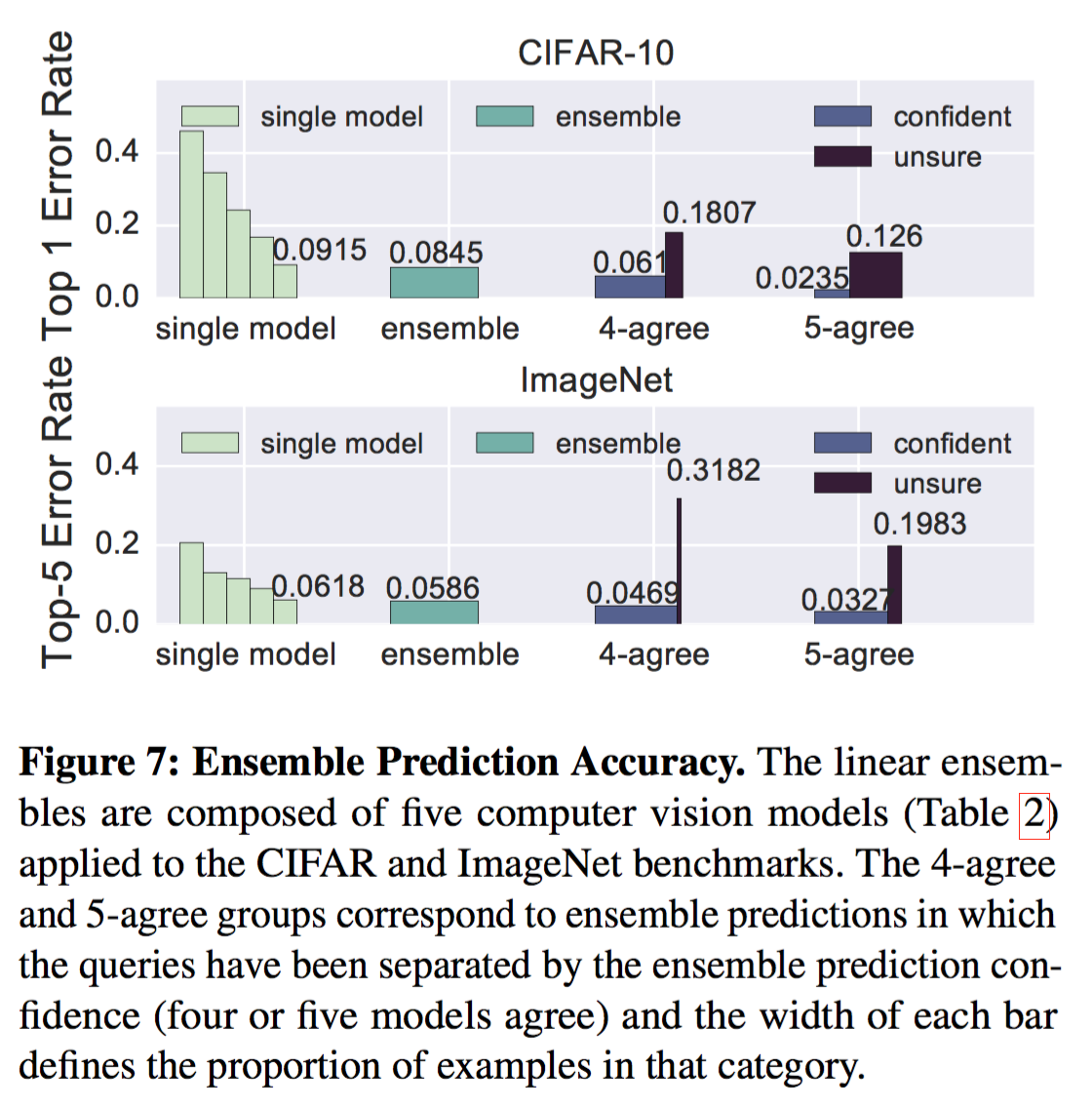
在Clipper中我们使用线性融合方法,计算加权平均的模型预测结果。在图7中我们展示了两种线性融合基线的预测错误率,整理来说对都能降低错误率。在ImageNet基线中,融合方法减少了5.2%的错误率。尽管看着效果有限,但是在计算机视觉的任务中,非常小的改进也被认为是非常重要的。Exp4算法随着模型数量的增加,准确率也会逐步提升。准确率提升带来了增长的计算开销,因为每条样本要在所有的模型中都要进行计算。
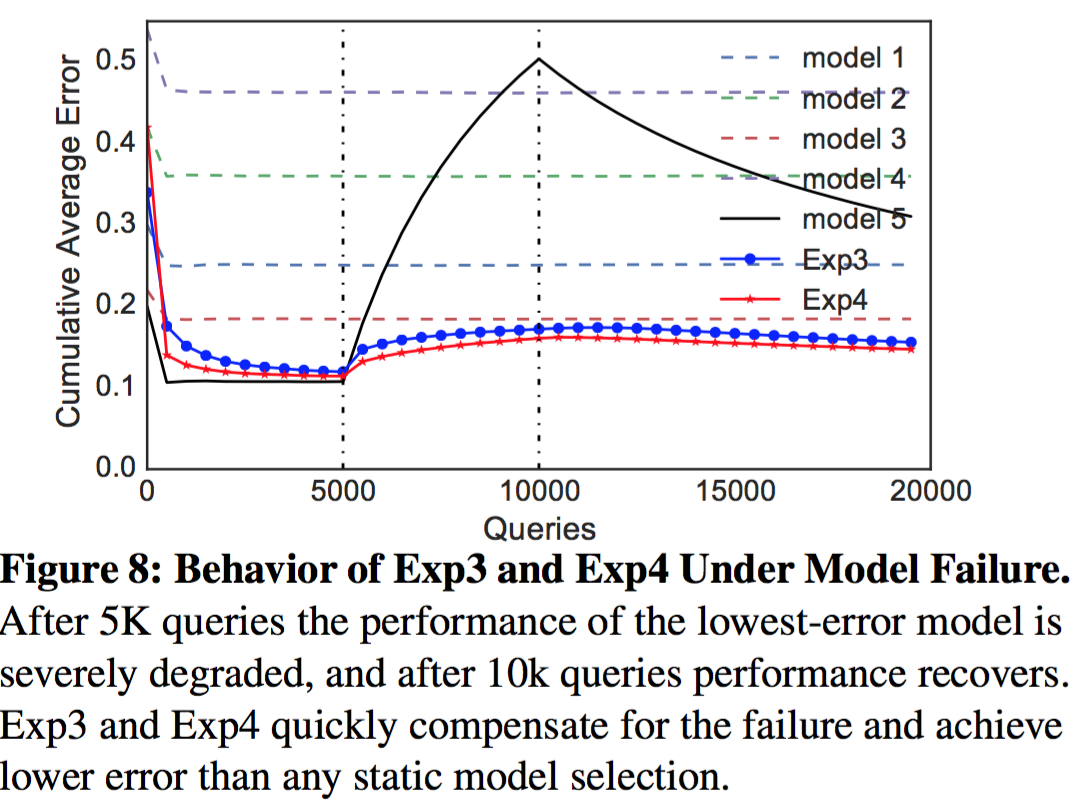
部署模型的准确率随着时间会逐渐降低。Clipper在线选择策略可以通过前端的反馈信息自动检测失败的情况,通过切换到另外一个模型(Exp3)或者对失败的模型进行降权(Exp4)。为了评估模型选择可以迅速有效地根据模型准确度变化而变化,我们模拟了一个根据收到的反馈来进行模型降权的实验。使用CIFAR数据集来训练五种不同的Caffe模型,模拟20K连续请求+实时反馈,每过5K请求我们会降低最优模型的准确率,然后最后模型会在10K请求以后进行恢复。图8中我们画出了分别针对单一和融合模型选择策略对应的累积平均错误率。最开始的5K请求,策略可以迅速收敛到最好模型(model 5)的效果。当模型5的错误率上升凸出尖角的时候,模型选择策略很快就把请求切换到别的模型。当10K请求的时候模型5开始回复,模型选择策略开始逐步开始将请求恢复发往模型5。
鲁棒的预测(robust prediction)
在线模型选择策略不只可以发现模型失败,利用新的模型来提升效果。对于很多实时的预测请求来说,也可以显著的提升终端用户的体验。例如终端应用在使用预测结果的时候不能不考虑置信度,盲目的使用所有预测的结果,而应该设置一个置信度的阀值。当预测的置信度低于阀值的时候,应用需要使用默认的决策从而避免重大的线上错误。同时从多个模型获取预测结果,我们可以获得置信度的评估结果。终端用户使用置信度分数来决定是否使用预测的结果。
落后者优化(straggler mitigation8)
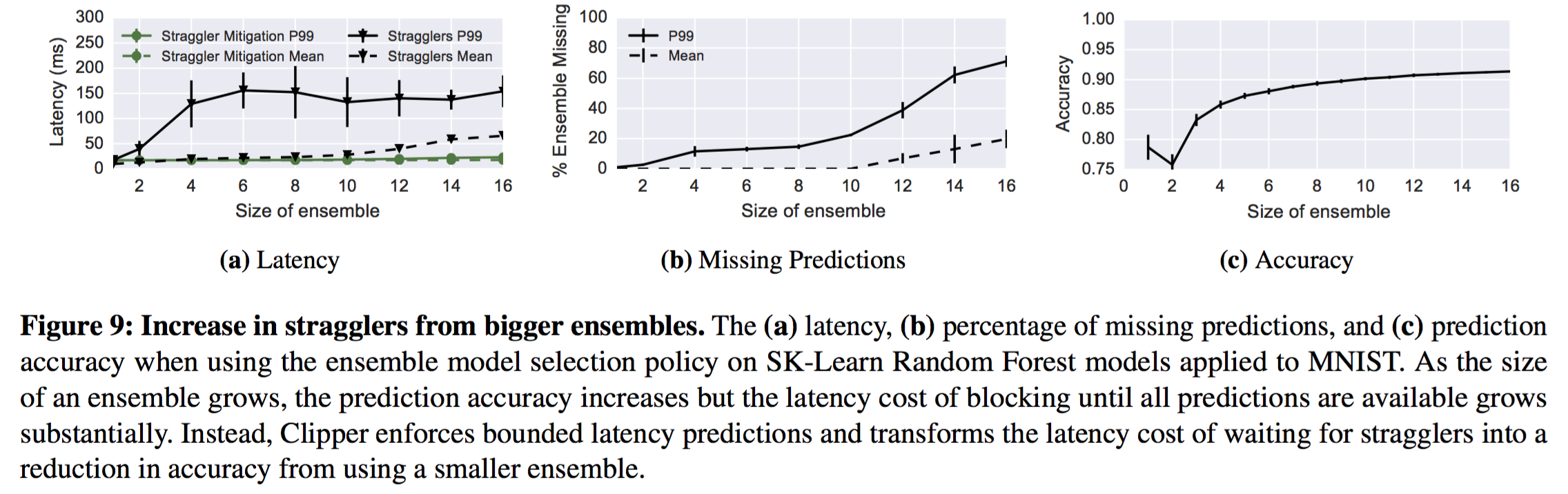
模型融合选择策略可以提高预测准确度,减少不确定性,同时也会带来额外的系统开销。当增加融合模型的大小,预测的代价也会相应增加。我们可以通过扩展模型抽象层来应对。与此同时,增加模型容器也会增加straggler影响长尾延迟的概率。在一个高延迟的请求比一个不那么精确的请求更差劲的前提下,Clipper采用straggler-mitagation策略。对于每一条请求,模型选择层都会保存一个延迟的SLO指标。在延迟过期时间到来的时候,_combile_函数可以使用预测的部分结果来进行融合。stragger-mitigation策略阻止了模型容器长尾延迟后向传递到前端应用。不过,这个策略会减少融合模型的个数。在图9b中我们画出了融合模型个数减少的情况,可以发现随着长尾延迟增加,大多数请求都是在延迟的截至时间前完成的。图9c中画出了在准确度与融合模型减少的时候的对应关系。
上下文(Contextualization)
在很多预测任务中特定模型预测的准确度跟上下文信息强相关的。例如,在语音识别中,一个模型可能训练的适合一部分人,对另外一部分人效果可能就会很差。对这种情况,选择合适的模型或者组合模型非常困难,但在模型选择层可以根据回调解决这个问题。为了支持特定上下文的模型选择,模型选择层需要针对特定的人或者场景或者session来配置一个单独的模型选择状态。上下文的状态信息会存储到一个额外的存储系统里,这里我们使用Redis来存储状态信息。
为了表明个性化的模型选择是可以带来额外收益的,我们训练并收集了针对不同方言的TIMIT语音识别模型,然后分别评估使用所有方言数据集训练的单一模型、用户指定的方言模型以及Clipper融合选择策略的预测错误率(图10)。我们发现明确的方言模型比未知方言的模型效果要好,表明上下文信息是可以提高预测的准确度的。同时也发现融合选择策略通过使用反馈信息可以非常快的找到效果好的混合模型。

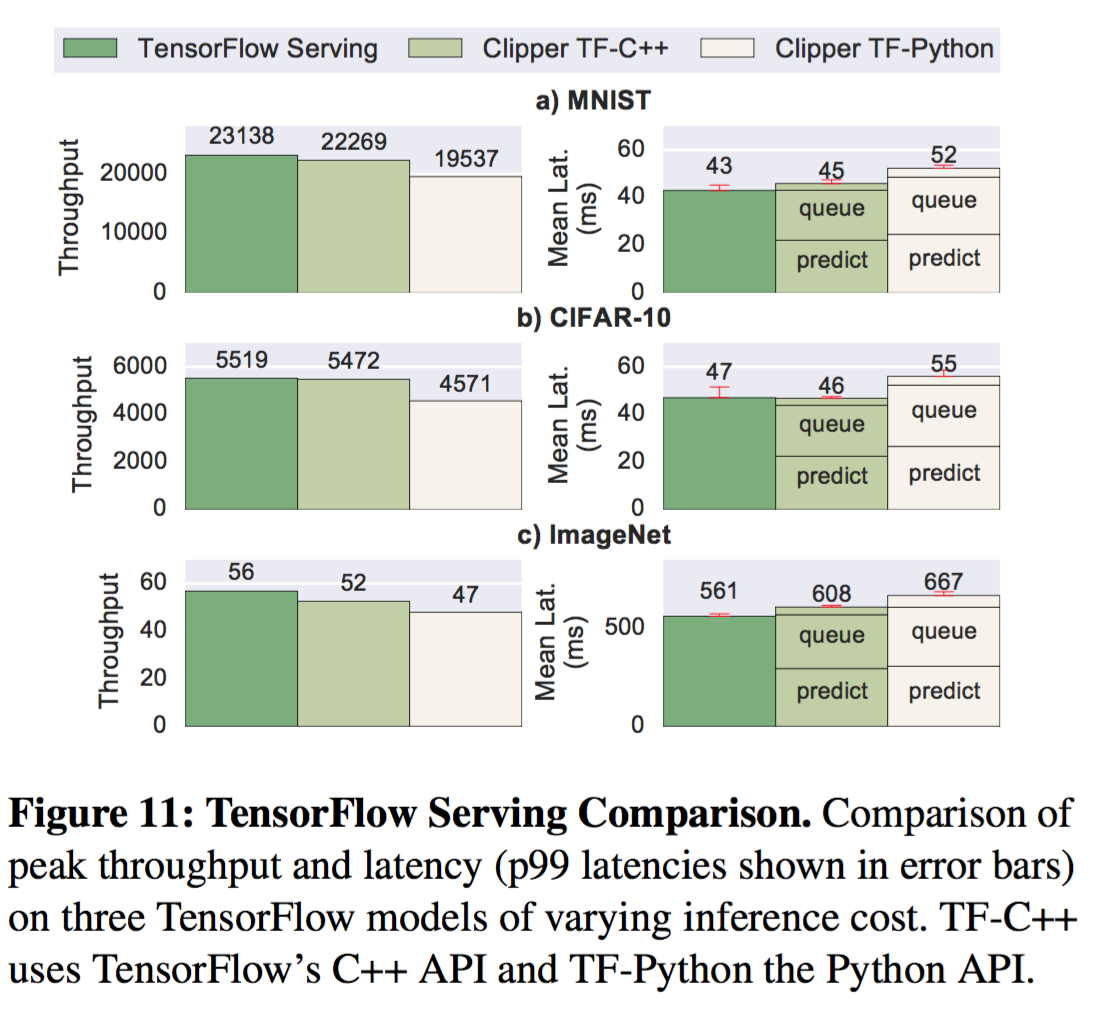
系统比较(System Comparison)
总结
本片论文为了解决预测服务中三个关键指标(延迟、吞吐量、准确度),提出了一种新的分层架构Clipper。Clipper将终端用户与各种不同的机器学习框架隔离开来,并提供统一的预测接口。终端用户无需感知任何变化就可以在这套架构上添加新的机器学习框架或者模型。通过Clipper的模型抽象层来解决了预测服务中的延迟与吞吐的问题。模型抽象层采用缓存和自适应打包策略实现了吞吐量提升26倍,同时满足了长尾延迟的需求, 支持集群的服务扩容。在模型选择层中解决预测准确度的问题,模型选择层支持同时部署多个模型,以及动态选择模型并对多模型预测结果进行组合。通过模型选择层可以实现更加鲁棒、准确、支持上下文的模型预测。评估Clipper的时候采用了四种标准的机器学习基准数据集,涉及语音识别、计算机视觉等。与Google Tensorflow在线服务系统比较, 在吞吐与延迟的指标上持平,说明了Clipper这种基于容器的结构和额外的功能可以最小化性能的损失。
参考资料
原始论文地址Clipper: A Low-Latency Online Prediction Serving System↩︎
straggle mitigation: Stragglers in general are those tasks that take more time to complete than their peers. This could happen due to many reasons such as load imbalance, I/O blocks, garbage collections, etc.↩︎
J. Nagle. Congestion control in ip/tcp internetworks. SIG- COMM Comput. Commun. Rev., 14(4):11–17, Oct. 1984↩︎
straggle mitigation: Stragglers in general are those tasks that take more time to complete than their peers. This could happen due to many reasons such as load imbalance, I/O blocks, garbage collections, etc.↩︎