LLaMA(Large Language Model Meta AI)论文阅读
0. 简介
LLaMA 训练了从7B到65B不同参数量的模型,从Hoffmann的论文【Training compute-optimal large languag】中证明了在有限计算代价的情况下(给定总的FLOPs大小),表现最好的不是参数量最大的模型,而是在更多数据上训练的稍小的模型。
LLaMA实现了两个目标: 1. LLaMA-13B跟GPT-3相比, 参数量小了10倍,但效果更好;LLaMA-65B比Chinchilla-70B和PaLM-540B更好。 2. 只依赖公开的开源数据集也可以达到最好的SOTA效果。
1. 论文阅读
1.1 训练数据
使用了多数据集的混合,对相应数据集做了对应的清理,例如重复数据去重、针对CommonCrawl训练了一个分类模型用于过滤没有被Wikipedia引用的低质量数据等。整体的训练数据包含总共有1.4T个token。
| Dataset | Sampling prop. | Epochs | Disk size |
|---|---|---|---|
| CommonCrawl | 67.0% | 1.10 | 3.3 TB |
| C4 | 15.0% | 1.06 | 783 GB |
| Github | 4.5% | 0.64 | 328 GB |
| Wikipedia | 4.5% | 2.45 | 83 GB |
| Books | 4.5% | 2.23 | 85 GB |
| ArXiv | 2.5% | 1.06 | 92 GB |
| StackExchange | 2.0% | 1.03 | 78 GB |
Sampling prop表示抽样比例Epochs表示当在1.4T tokens训练时作用到不同数据集的epoch数
1.2 tokenizer
1.2.1 BPE(Byte pair encoding)
使用BPE(Byte pair encoding)进行tokenizer,BPE方法是一种简单又鲁棒的数据压缩方法,基本思路是对于一个句子中连续字符使用一个新的字符进行替换,从而达到数据压缩的作用,对数据还原时才用lookup查表的方式,依次反向对字符进行反向替换恢复数据。
例如对aaabdaaabac压缩,依次通过如下方式进行替换:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17# 1. 原始字符串
aaabdaaabac
# 2. 使用Z替换aa
ZabdZabac
Z=aa
# 3. 使用Y替换ab
ZYdZYac
Y=ab
Z=aa
# 4. 使用X替换ZY
XdXac
X=ZY
Y=ab
Z=aa
1.2.2 SentencePiece
SentencePiece是google对BPE思想的一种实现,除了BPE还实现了unigram language model,LLaMA使用SentencePiece进行tokenizer。
1.3 LLaMA模型结构
整体模型基于transformer结构,在此基础上整合了多个其他模型中的改动方法,具体如下:
* Pre-normalization [GPT3]:使用RMSNorm(Root Mean Square Layer
Normalization)方法对transformer每层的输入进行归约(norm)操作,代替了transformer之前对输出进行归约(norm)。
* SwiGLU activation function
[PaLM]:使用SwiGLU激活函数代替Relu激活函数,跟PaLM不同的是dimension维度从4d变为了2/34d。
Rotary Embeddings
[GPTNeo]:去除了transformer中绝对位置embedding,使用旋转式的位置embedding。
1.4 训练参数配置
- 使用
AdamW优化器,对应超参beta1=0.9, beta2=0.95; 使用cosine学习率调度,最终学习率是最大学习率的10%;weight decay为0.1, gradient clipping为0.1。 - 训练使用前2000个step进行warmup
- 不同规模的模型大小如下:
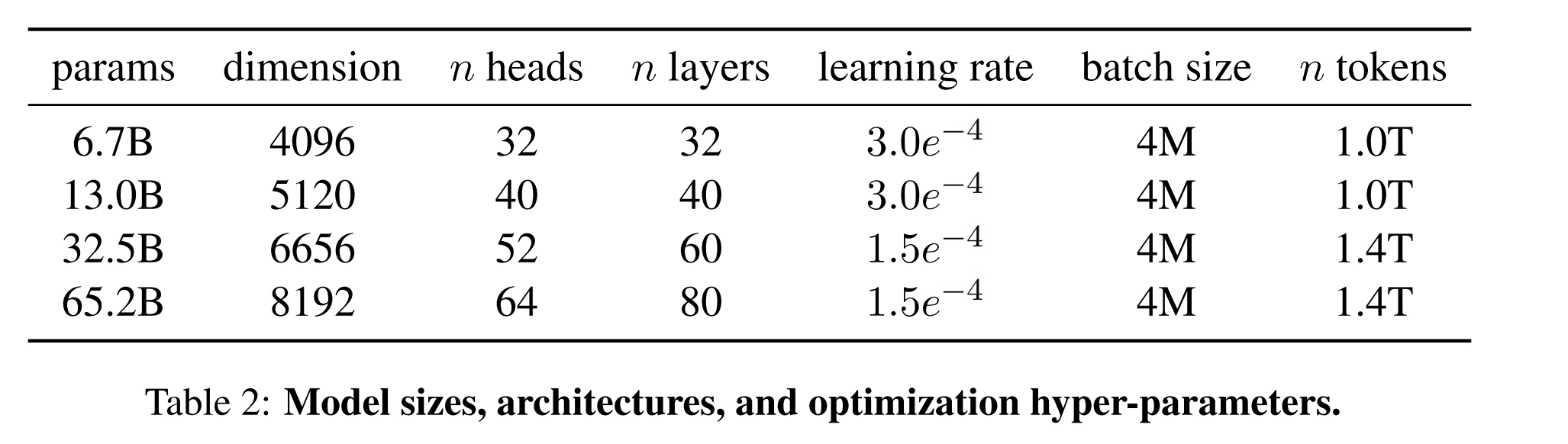
1.5 高效实现
使用了如下方式提升模型训练的速度: *
使用causal multi-head attention进行显存降低。对应实现是【xformers】。在这个方法中不用存储attention的权重,同时不用计算被masked的key/query的分数。
*
在反向pass中使用checkpointing的方法减少激活的重计算。这里不能使用pytorch默认的autograd,需要手动实现transformer的反向。
* 使用model并行和sequece并行。对应megatron3中的优化【Reducing Activation
Recomputation in Large Transformer Models】。 *
将activation的计算和不同gpu卡的通信(all_reduce操作)进行重叠
训练65B参数的模型,使用了2048块80G显存大小的A100卡,处理对应380
tokens/sec/GPU,1.4T个token训练了有21天。训练loss如下: 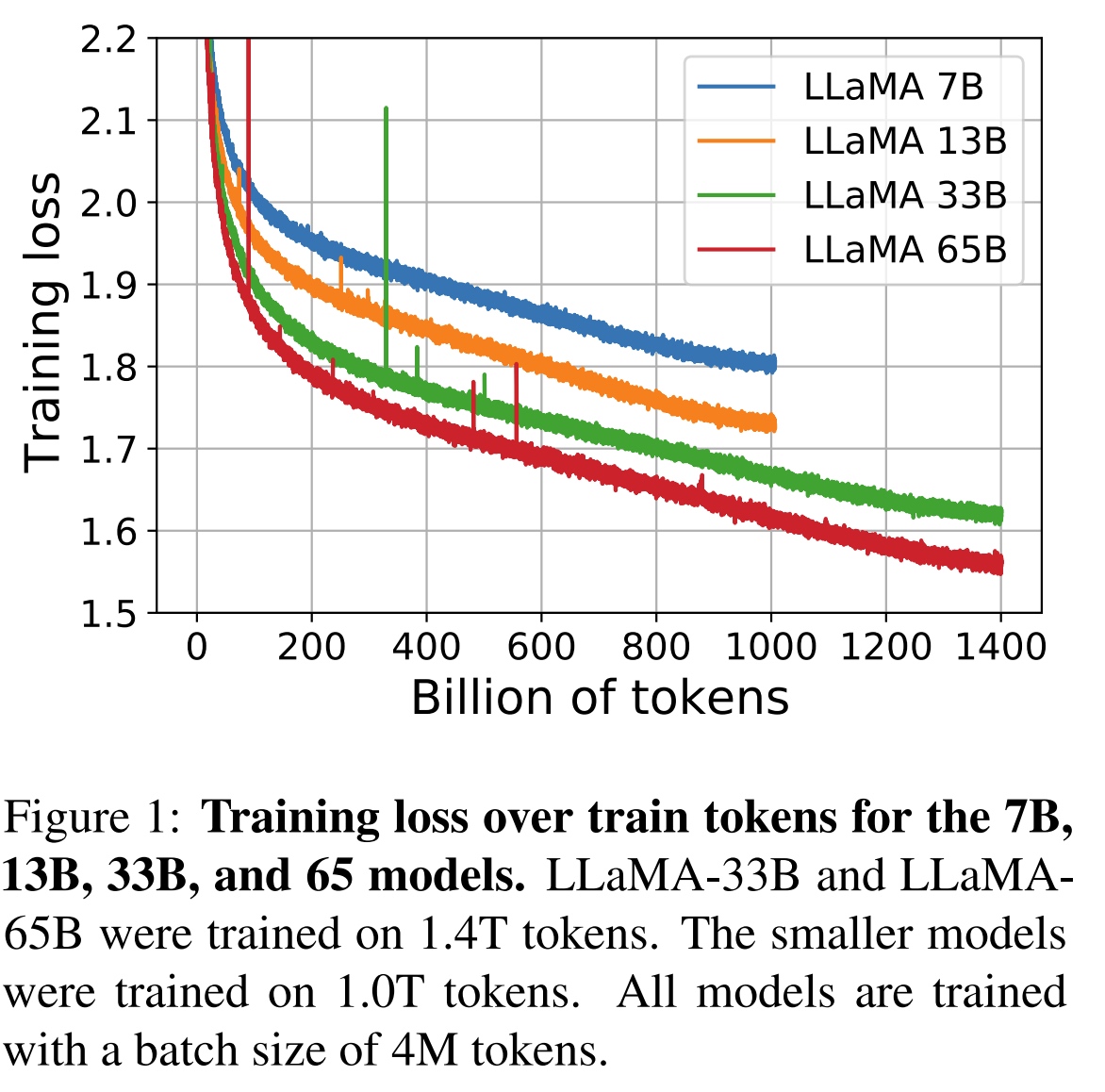
1.6 结果说明
结果参考论文【3 Main results】
2. 参考
- facebookresearch/llama
- LLaMA: Open and Efficient Foundation Language Models
- Byte pair encoding
- SentencePiece
- unigram language model
- google/sentencepiece
- Stupid Backoff
- Stupid Backoff implementation clarification
- PaLM
- Training Compute-Optimal Large Language Models
- Reducing Activation Recomputation in Large Transformer Models
- Root Mean Square Layer Normalization