DeepSeek-V2论文
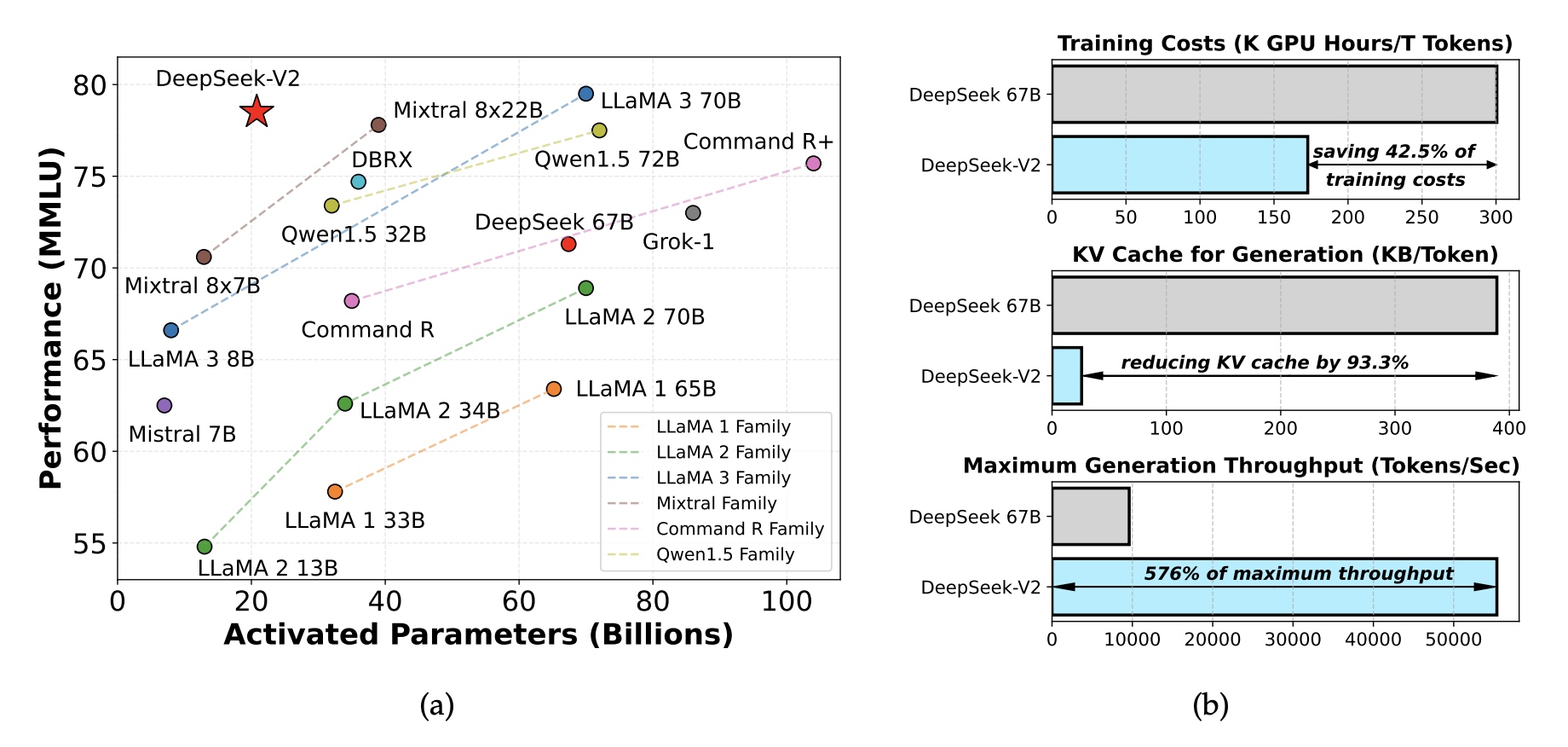
DeepSeek-V2是MoE模型架构,有236B总的参数量,每个token会激活其中的21B的参数,支持128K token长度的上下文。在DeepSeek-V2中采用了Multi-head Latent Attention (MLA)和DeepSeekMoE的架构设计。相比DeepSeek-67B实现了42.5%训练成本下降,KV Cache减少93.3%,生成吞吐最高提升了5.76倍。先使用8.1T训练数据进行了DeepSeek-V2的预训练,然后进行SFT和RL训练发挥更大潜能。
1. 总体架构
DeepSeek-V2整体也是采用Transformer架构,每个Transformer Block包含一个attention模块与FFN网络。在attention中新设计了MLA结构,使用低秩KV压缩方法消除了KV Cache在推理时大小瓶颈问题;对于FFN网络采用了DeepSeekMoE的设计。还有一些其它模块像layer_norm/激活函数等,如无特别说明,跟DeepSeek-67B保持一致。具体结构如下图所示。
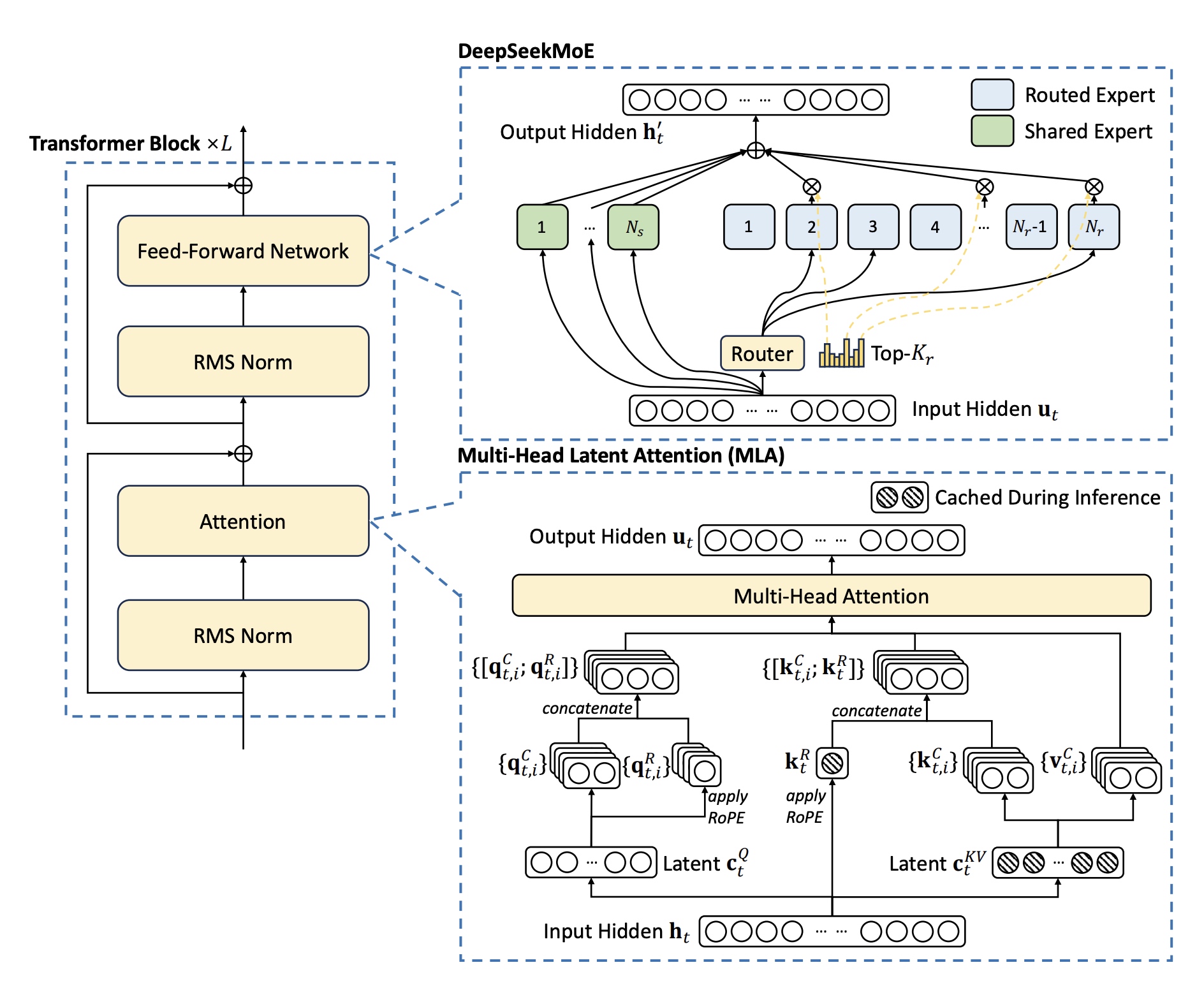
1.1 Multi-Head Latent Attention(MLA)
先回顾下标准的Attention实现,\(d\) 表示embedding维度,\(n_h\) 表示attention head的个数,\(d_h\) 表示每个单个head的维度,\(h_t \in \mathbb{R}^d\) 表示第 \(t\) 个token的attention的输入。标准的 \(MHA\) 首先会先基于权重值 \(W^Q, W^K, W^V \in \mathbf{R^{d_h n_h \times d}}\) 计算q/k/v向量 \(\mathbf{q_t, k_t, v_t} \in \mathbf{R^{d_h n_h}}\) .

接着, \(\mathbf{q_t, k_t, v_t}\) 会被分到 \(n_h\) 个head上进行计算,\(\mathbf{q_{t,i}, k_{t,i}, v_{t,i}} \in \mathbf{R^{d_h}}\) 表示第i个attention head对应的query/key/value的值。 \(W^O \in \mathbf{R^{d \times d_n n_h}}\) 表示输出映射矩阵。推理中采用KV cache方式进行加速,MHA对于每个token要缓存 \(2 n_h d_h l\) 个元素,缓存取决于最大的batch数与sequence长度。
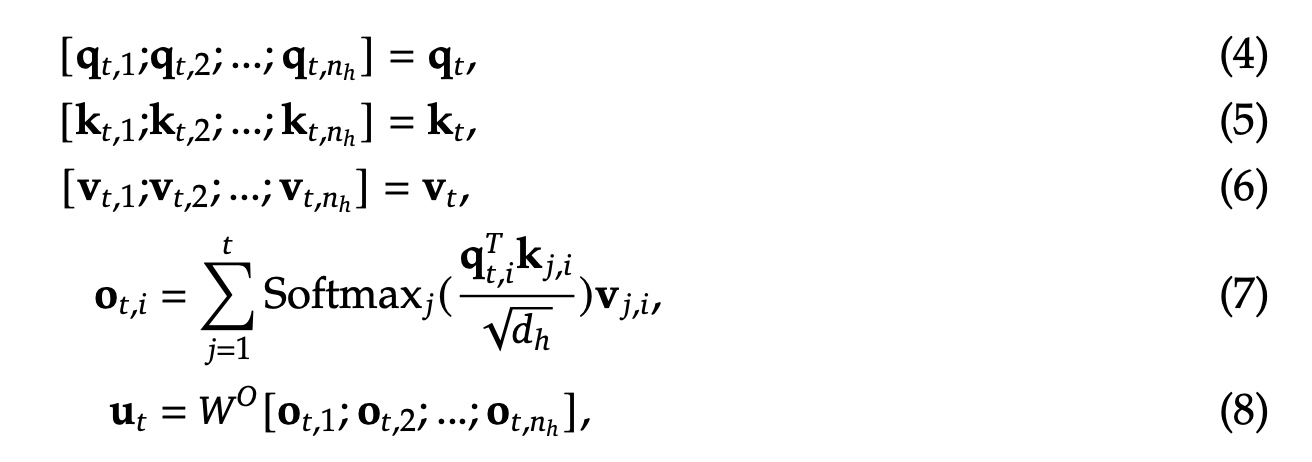
MLA中核心是低秩key-value压缩,其中 \(c_t^{KV} \in \mathbf{R}^{d_c}\) 是KV压缩的隐向量; \(d_c(<< d_h n_h)\) 表示KV压缩的维度; \(W^{DKV} \in \mathbf{R}^{d_c \times d}\) 是下映射矩阵; \(W^{UK}, W^{UV} \in \mathbf{R}^{d_h n_h \times d_c}\) 是对于key和value的上映射矩阵。在推理时,MLA只用缓存 \(c_t^{KV}\) , 这样KV cache中只会保存 \(d_c l\) 个元素,\(l\) 表示layer的层数;同时 \(W^{UK}\) 可以放到 \(W^Q\) 中,\(W^{UV}\) 可以放到 \(W^O\) 中,这样不需要单独有一步来计算attention的key和value值。

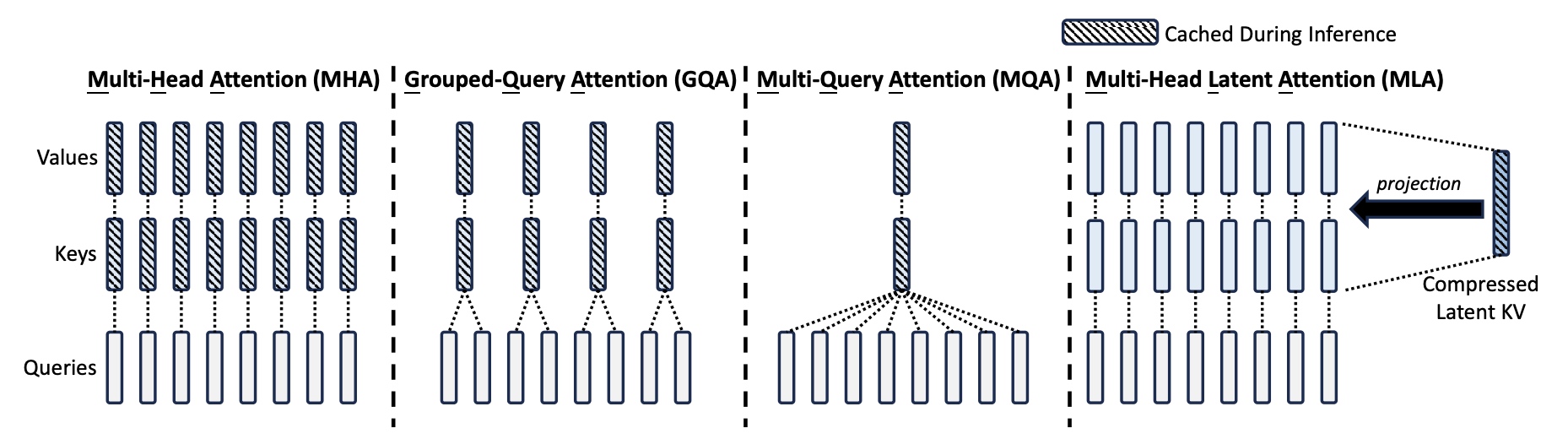
MHA/GQA/MQA/MLA几种方式区别如下:
另外,为了减少训练过程中的激活大小,对于query也可以使用低秩压缩,\(c_t^Q \in \mathbf{R}^{d'_c}\) 是query的压缩隐矩阵,\(d'_c(<< d_h n_h)\) 表示query的压缩维度,\(W^{DQ} \in \mathbf{R}^{d'_c \times d}, W^{UQ} \in \mathbf{R}^{d_h n_h \times d'_c}\) 分别是query的下映射矩阵和上映射矩阵。

1.2 解耦旋转位置嵌入(Decoupled Rotary Position Embedding)
RoPE与低秩压缩方法不能直接结合使用,RoPE对于key和query来说是位置相关的,如果应用了RoPE,在公式(10)中 \(k_t^C, W^{UK}\) 会与RoPE相互耦合,这样计算时 \(W^{UK}\) 就不能放到 \(W^Q\) 中一起计算。因此提出了Decoupled RoPE的方法来改进。
使用额外解耦用的query向量 \({q_{t,i}^R \in \mathbf{R}^{d_h^R}}\) 和key向量 ${k_t^R} {d_hR} $ 用于RoPE,\(d_h^R\) 表示单个head上解耦query和key的维度大小。这里的 \(W^{QR} \in \mathbf{R}^{d_h^R n_h \times d'_c}, W^{KR} \in \mathbf{R}^{d_h^R \times d}\) 是用来生成解耦的query和key的权重矩阵;\(RoPE(\cdot)\) 表示RoPE操作; \([\cdot;\cdot]\) 表示concat拼接操作。对于推理来说,解耦用的key也需要被cache住, DeepSeek-V2需要保存 \((d_c + d_h^R)l\) 个元素。
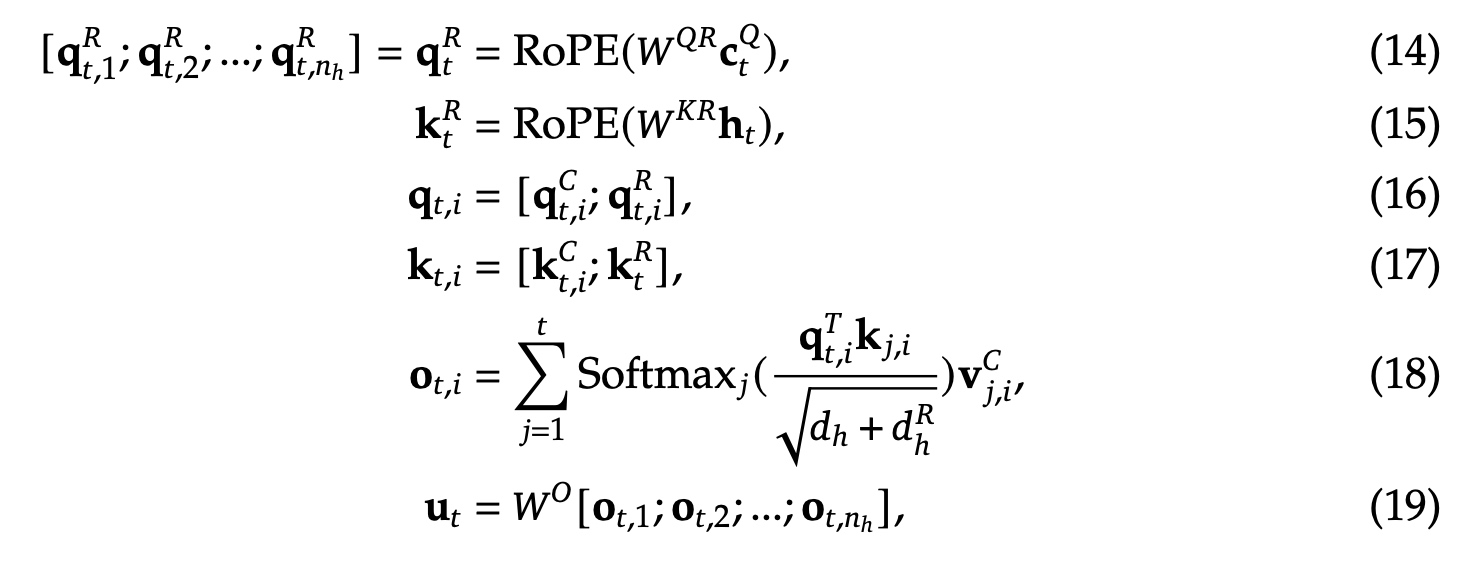
以下对比了MHA/GQA/MQA/MLA几种方式的KV Cache保存的元素个数,MLA相当于有2.25个group的GQA版本,但性能比MHA更强。这里 \(n_h\) 表示head头的个数,\(d_h\) 表示每个head的维度,\(n_g\) 表示GQA group的个数,\(d_c\) 表示解耦的query与key的压缩维度,\(d_h^R\) 表示单个head解耦的query与key的压缩维度。对于DeepSeek-V2来说,\(d_c=4d_h, d_h^R=\frac{d_h}{2}\).
1.3 DeepSeekMoE
1.3.1 基础结构
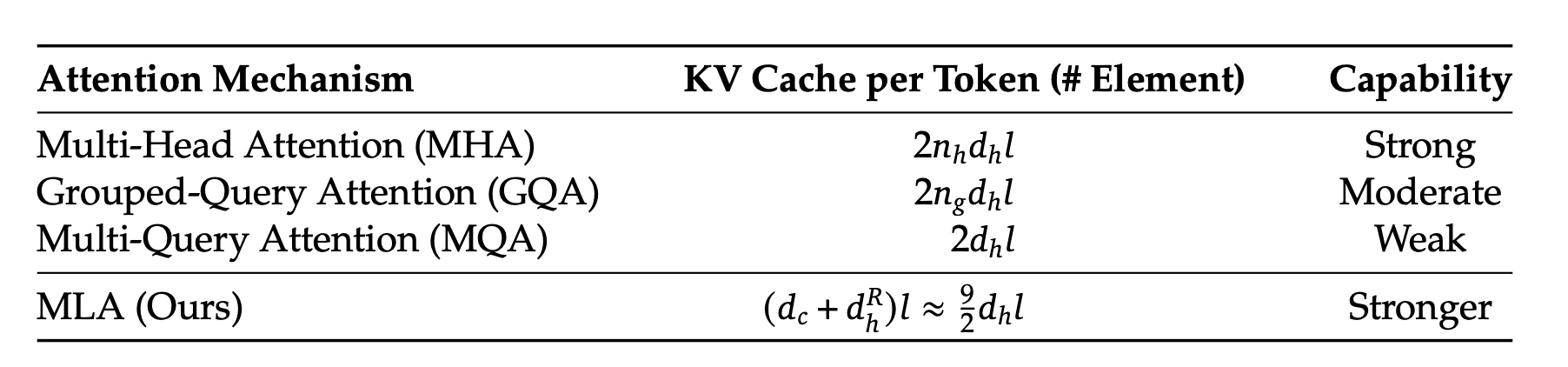
从训练资源节省上来看选择DeepSeekMoE做为基础架构,这里 \(\mathbf{u}_t\) 表示输入的第 \(t\) 个token,\(\mathbf{h}'_t\) 表示FFN的输出,\(N_s, N_r\) 分别表示共享专家个数与路由专家个数, \(FFN_i^{(s)}(\cdot)、FFN_i^{(r)}(\cdot)\) 分别表示第 \(i\) 个共享专家与路由专家,\(K_r\) 表示激活的路由专家个数,\(g_{i,t}\) 表示第i个专家的门控值,\(s_{i,t}\) 表示token分发给专家的仿射值(affinit), \(\mathbf{e}_i\) 表示第i个路由专家的中心值,\(Topk(\cdot, K)\) 表示第t个token计算出来的前 \(K\) 高的专家仿射分数。

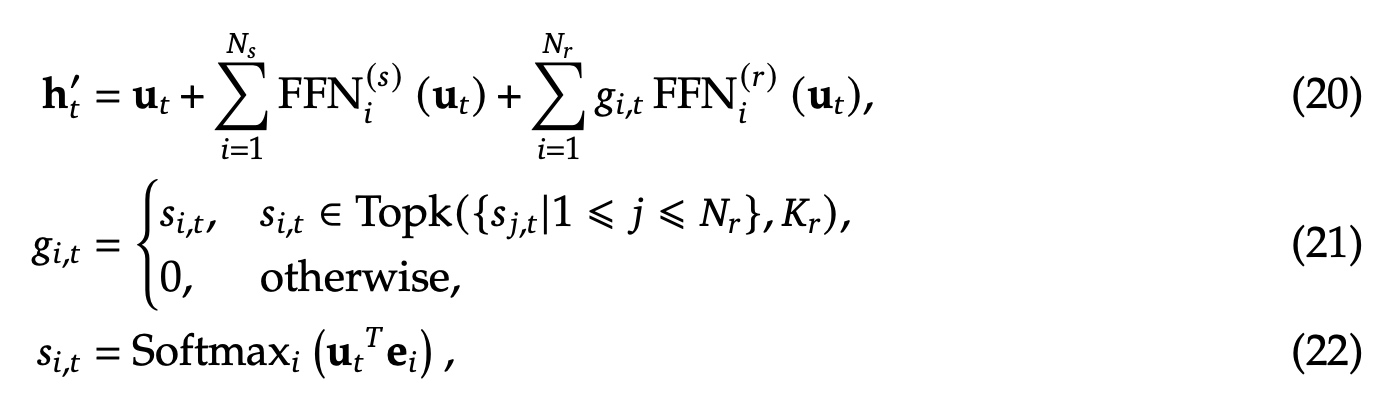
1.3.2 路由的设备限制
在专家并行中,专家会分布到不同的卡上。对于每个token来说,MoE通信量与卡的个数成正比。由于在DeepSeekMoE中对专家进行了细粒度拆分,所以MoE通信时涉及的卡的个数就更多了。在DeepSeek-V2中在topK基础上增加了卡分布的限制,限制每个token分发的专家最多分布在M个卡。具体做法是先找到具有最高score的前M个卡,然后从这M个卡里选top-K的专家。实验发现,当M>=3时,这个效果是明显的。
1.4 用于负载均衡的辅助loss设计
为了避免不均衡路由导致个别专家学习不充分,以及训练效率低下,训练时设计了用于负载均衡自动学习策略的loss函数,分为专家级别的负载均衡( \(\mathcal{L}_{ExpBal}\) )、卡级别的负载均衡( \(\mathcal{L}_{DevBal}\) )、通信级别的负载均衡( \(\mathcal{L}_{CommBal}\) ).
专家级别的负载均衡( \(\mathcal{L}_{ExpBal}\) )跟DeepSeekMoe类似,\(\alpha_1\) 是专家级别loss的超参数,\(\mathbf{T}\) 表示sequence中token的总个数,\(\mathbb{1}(\cdot)\) 表示指示函数(满足条件才为1)。

卡级别的负载均衡( \(\mathcal{L}_{DevBal}\) )跟DeepSeekMoe类似,\(\alpha_2\) 是卡级别负载均衡的超参系数。

通信级别的负载均衡( \(\mathcal{L}_{CommBal}\) )是因为虽然有卡级别负载均衡保证对于每个token来说,发送通信的卡的个数是固定的,但是有可能个别卡会收到比较多的token,这时通信效率会有影响。\(\alpha_3\) 是超参系数;具有device个数上限的卡级别负载均衡策略会保证一个时刻最多有 \(MT\) 个隐状态会被发送给别的卡;类似的,通信级别负载均衡会保证一个时刻最多会接收到 \(MT\) 个隐状态,从而提升通信效率。

1.4 token丢弃策略
负载均衡loss不能严格保证均衡,为了减少计算浪费设计了卡级别的token丢弃策略,每个设备上的容量系数(capacity factor)设为了1,
当到达计算瓶颈时,会丢弃每个卡上分数最低的token的,直到达到目标。另外会保证10%的训练sequence不会被丢弃。会根据计算效率动态决定要不要在推理过程中丢弃token,保证训练和推理策略的一致性。
2. 预训练
训练数据有8.1T个token, 中文token占比12%大于英文的;使用Byte-level Byte-Pair Encoding (BBPE) 分词算法,词表大小为100K。
模型transformer层数为60层,hidden_size为5120,MLA中head个数(\(n_h\))为128个,每个head的维度(\(d_h\))为128,KV压缩的维度(\(d_c\))为512,query压缩维度(\(d'_c\))为1536,对于解耦的query与key的单head维度(\(d_h^R\))为64;每个MoE层有2个共享专家与160个路由专家,每个专家的隐层维度为1536,每个token会激活其中的6个专家。在实际中,压缩的隐向量后加上了RMS Norm Layer层.
DeepSeek-V2总的有236B参数量,每次激活其中的21B参数量。
预训练的sequence长度为4K,后面训练完以后使用YaRN方法进行上下文扩展从4K扩到128K。后面还使用了上下文32K的训练数据进行后训练,每个batch大小为576个sequence.
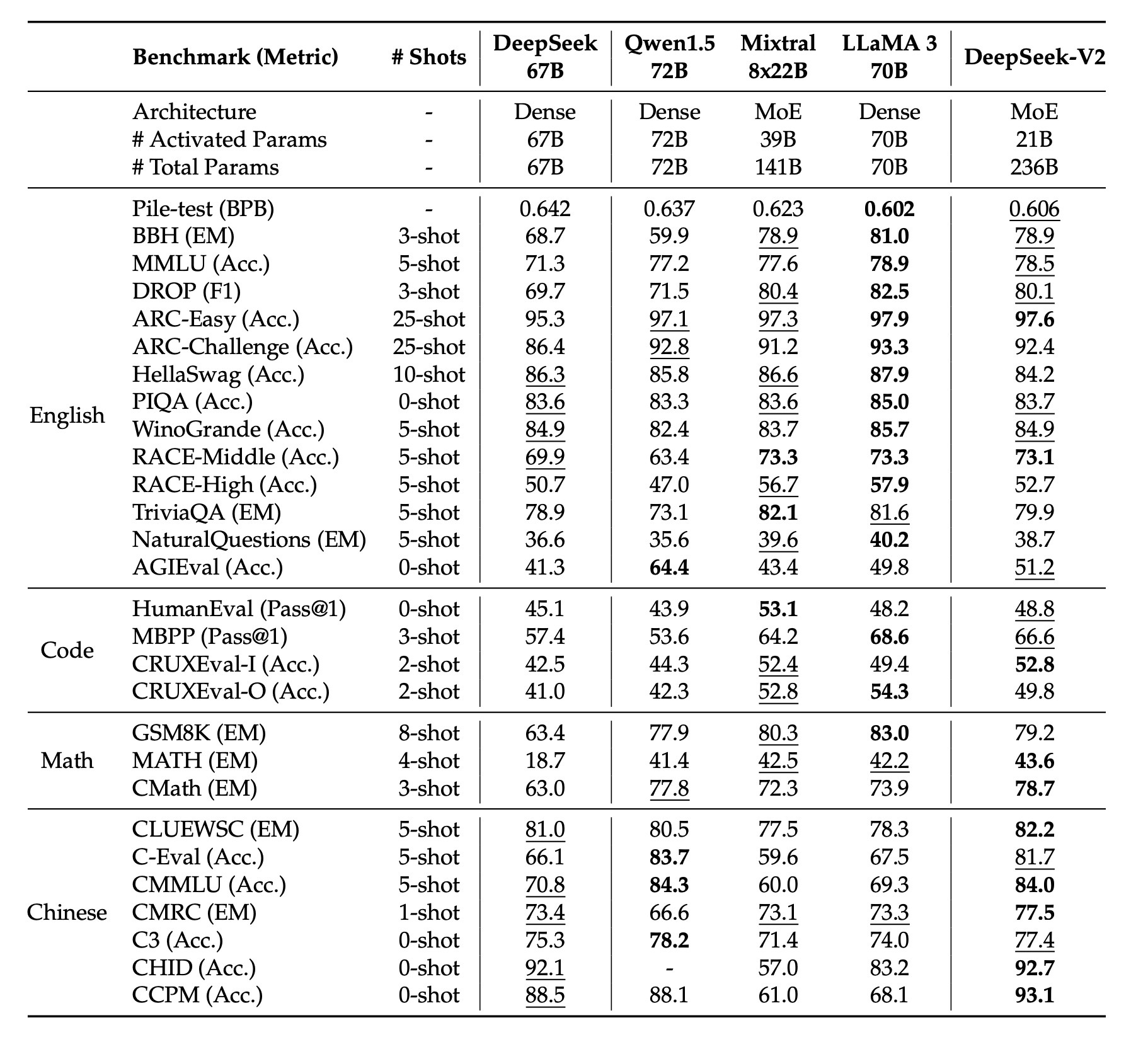
最终效果如下:
3. DeepSeek-V2-Lite
DeepSeek-V2-Lite版本有15.7B参数量,每个token激活2.4B参数量,模型有27层,2048的hidden_size, MLA有16个attention头,KV压缩维度为512,与DeepSeek-V2不同的是不对query进行压缩;也是采用DeepSeekMoe结构,包括2个共享专家和64个路由专家,每个专家维度是1408, 每次会激活其中的6个专家。
配置与评测效果如下:
