Grouped Query Attention论文阅读
论文:GQA: Training Generalized Multi-Query Transformer Models from Multi-Head Checkpoints
1. 背景介绍
Google在2023年发表的一篇关于Transformer Attention的论文,整体论文写的清晰易读,思想简单但很好用。论文名字简写是GQA,但实际分别代表了两种缩写: 1. Generalized Multi Query Attention 2. Grouped Query Attention
2. 详细介绍
2.1 通用Multi-Query Attention
在之前的Multi-Query
Attention【\(MQA\)】方法中只会保留一个单独的key-value头,这样虽然可以提升推理的速度,但是会带来精度的损失,这篇论文的第一个思路是基于多个\(MQA\)的checkpoint进行finetuning,来得到了一个质量更高的\(MQA\)模型。这个过程也被称为Uptraining。
具体分为两步: 1. 对多个\(MQA\)的checkpoint文件进行融合,融合的方法是通过对key和value的head头进行mean pooling操作,如下图。
2.
对融合后的模型使用少量数据进行finetune训练,重训后的模型大小跟之前一样,但是效果会更好

2.2 Grouped-query attention
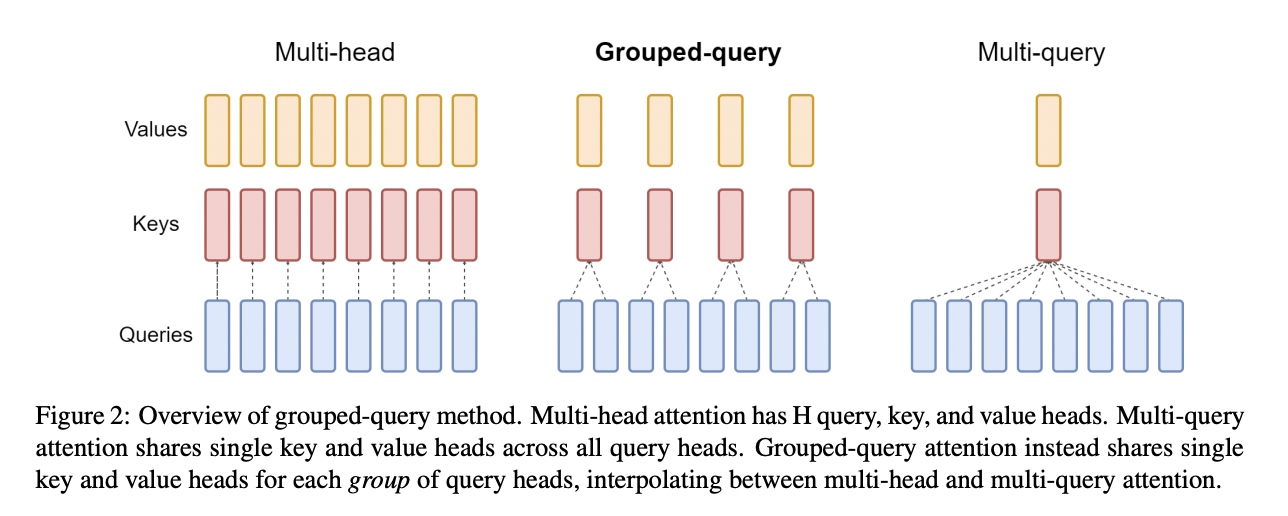
如下图所示,在一般的attention中是Multi-head多头结构,每个头有自己单独的key-value对;在Multi-query attention结构中只会有一组key-value对;在Grouped-query attention对attention进行分组操作,query被分为N组,每一组分别与一对key-value对进行映射。
在基于Multi-head多头结构变为Grouped-query分组结构的时候,也是采用跟2.1一样的方法,对每一组的key-value对进行mean pool的操作进行参数融合。融合后的模型能力更综合,精度比Multi-query好,同时速度比Multi-head快。
3. 应用
在llama2中有用到GQA,
在推理过程中由于多个query会复用相同的key-value对,所以对于KV-Cache存储会减少对key-value对的存储,减少了
n_heads / n_kv_heads
倍,这里的n_heads是原始Multi-head的头数,n_kv_heads是Grouped-query分组后每组中key-value对的数量。
在实际使用中,会根据从压缩后的key-value对进行还原操作,也就是repeat操作。在llama2中代码如下:
1 | # https://github.com/facebookresearch/llama/blob/4d92db8a1db6c7f663252bf3477d2c4b8bad2385/llama/model.py#L77 |
repeat_kv在github上一个示例如下, 假设repeat 2次操作:
1 | x = torch.rand(1, 2, 3, 4) |