SentencePiece论文阅读
1. 论文
1.1 基本使用
SentencePiece是用于NLP训练中对句子进行token化的工具,跟语言无关, SentencePiece中包含了byte-pairencoding(BPE)和unigram language model两种切分subword的算法。SentencePiece中包含有四个部分:- Normalizer: 规一化操作,类似Unicode把字符转为统一格式。
- Trainer: 从规一化后的语料中学习subword的切分模型。
- Encoder: 对应预处理时的tokenization操作,把句子转为对应的subword或id。
- Decoder: 对应后处理时的detokenization操作,把subword或id还原为原有句子
示例如下: 1
2
3
4
5
6
7
8
9
10
11
12
13
14
15% spm_train −−input=data/input.txt
−−model_prefix=spm −−vocab_size=1000
% echo "Hello world." | spm_encode
−−model=spm.model
_He ll o _world .
% echo "Hello world." | spm_encode
−−model=spm.model −−output_format=id
151 88 21 887 6
% echo "_He ll o _world ." |
spm_decode −−model=spm.model
Hello world.
% echo "151 88 21 887 6" |
spm_decode −−model=spm.model
−−input_format=id
Hello world.
1.2 设计
- SentencePiece中的Encoder和Decoder相互对应,公式定义为
Decode(Encode(Normalize(text))) = Normalize(text)。也被称为lossless tokenization。 - SentencePiece计算高效,BPE每轮需要
O(N^2)的计算量,但SentencePiece实现时使用了二叉堆(优先队列),使得效率降为了O(N*log(N))。 - SentencePiece词id的管理使用
--vocab_size=<size>, 相比BPE中使用合并次数的定义更通用。内置了一些词id,例如:unknown symbol(), BOS ( ), EOS ()和padding(). - SentencePiece默认的规一化采用了
Unicode NFKC, 在使用spm_train时指定规一化类型--normalization_rule_name=nfkc, 也支持自定义规一化操作--normalization_rule_tsv=<file>, 例如把unicode编码[U+41 U+302 U+300]转为U+1EA64。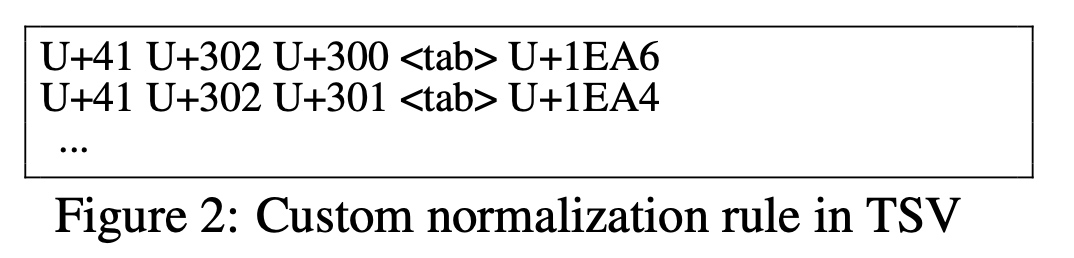
- SentencePiece使用是自包含的,所有的模型参数、规则、状态都被编码到了model文件中
- 提供了即时使用的Python、C++等API,例如:
1 | // c++ |
2. 代码
代码参考:https://github.com/google/sentencepiece