python中符号'*'和'**'的最全用法
0. 用法列表
- 在数值计算中使用
- 在函数定义和调用中使用
- 在迭代器(iterator)中使用
在Megatron-LM/Pytorch运行中报错如下: 1.
No module named 'fused_layer_norm_cuda':
apex没有装或者装的不对,注意直接用pip install
apex装的不是真正的nvdia-apex,必须通过源码编译安装 2.
ModuleNotFoundError: No module named 'packaging':
在新版的apex上编译会遇到报错,需要切换到之前的代码版本 3.
No module named 'amp_C': 编译指令使用
pip install -v --no-cache-dir --global-option="--cpp_ext" --global-option="--cuda_ext" ./,编译后还需要额外执行python setup.py install
4.
ImportError: libc10.so: cannot open shared object file: No such file or directory:
libc10.so是跟着pytorch一起装的
NVIDIA APEX 代码库:https://github.com/NVIDIA/apex
在python程序中,如何在命令行中传递布尔(bool)类型参数, 并在程序中解析使用? 在python中通常使用argparse进行参数解析, 常用的实现有以下几种方式。
在GPT(Generative pre-trained transformer)大火的今天回去重读了GPT在18年的开山之作【Improving Language Understanding by Generative Pre-Training】。在面对NLP众多种类任务(自然语言推理/问答/文档分类)时有大量无标注语料,相对而言,有标注的语料非常少。
为此论文提出一个新的训练思路: 先基于海量无标注语料进行通用的生成式预训练,然后针对下游任务使用有标注的数据进行finetune。这算是一个两阶段的半监督训练方法, 先后融合了无监督的预训练和有监督的finetune训练。
2019年OpenAI发布的模型,OpenAI在2018年的GPT1中给出了一种半监督的训练方法,在GPT2中针对如下问题做了升级: * 以前机器学习训练代价大,往往先要指定训练任务和高质量的标注数据集,且要保证训练数据和测试数据的分布相同,不同任务间无法复用;GPT2实现一个更通用的系统,支持多种NLP任务的学习,实现了Zero Shot。 * 大模型训练往往需要海量数据,准备高质量的标注数据集明显是不现实的;GPT2中支持使用网上公开的无标注的数据进行训练。
CLIP(Contrastive
Language–Image
Pre-training)是OpenAI第一篇关于多模态的论文,在2021年1月跟DALL・E一起发布。其中DALL・E用于文本生成图像,CLIP用于图像分类。CLIP跟之前常用的有监督图像分类相比不同,学习中结合了文本的语义信息(natural language supervision),可以实现类似GPT-3的zero-shot的能力。
CLIP有以下两个优势: * 大幅降低标注成本。之前标注都需要人手工标注大量高质量样本,现在通过搜索引擎自动构建4亿条图像-文本对用于训练。 * 迁移泛化能力强。做为预训练模型,跟特定任务解耦(task-agnostic),可以实现类似zero-shot的效果。
ViT是2020年的一篇paper,目前(2023年2月)在google引用超11000次,CV图像领域中被广泛使用。在ViT出来之前,Transformer架构已经在NLP领域大显身手,在CV领域还是用的CNN,通过ViT这篇paper在CV中正式引入Transormer,且效果不错。
在pytorch DDP数据并行时会对数据集进行切分,每个rank节点只处理部分数据。使用DistributedSampler来会把dataset数据集采样为一个子数据集。定义如下:
1 | torch.utils.data.distributed.DistributedSampler(dataset, num_replicas=None, rank=None, shuffle=True, seed=0, drop_last=False) |
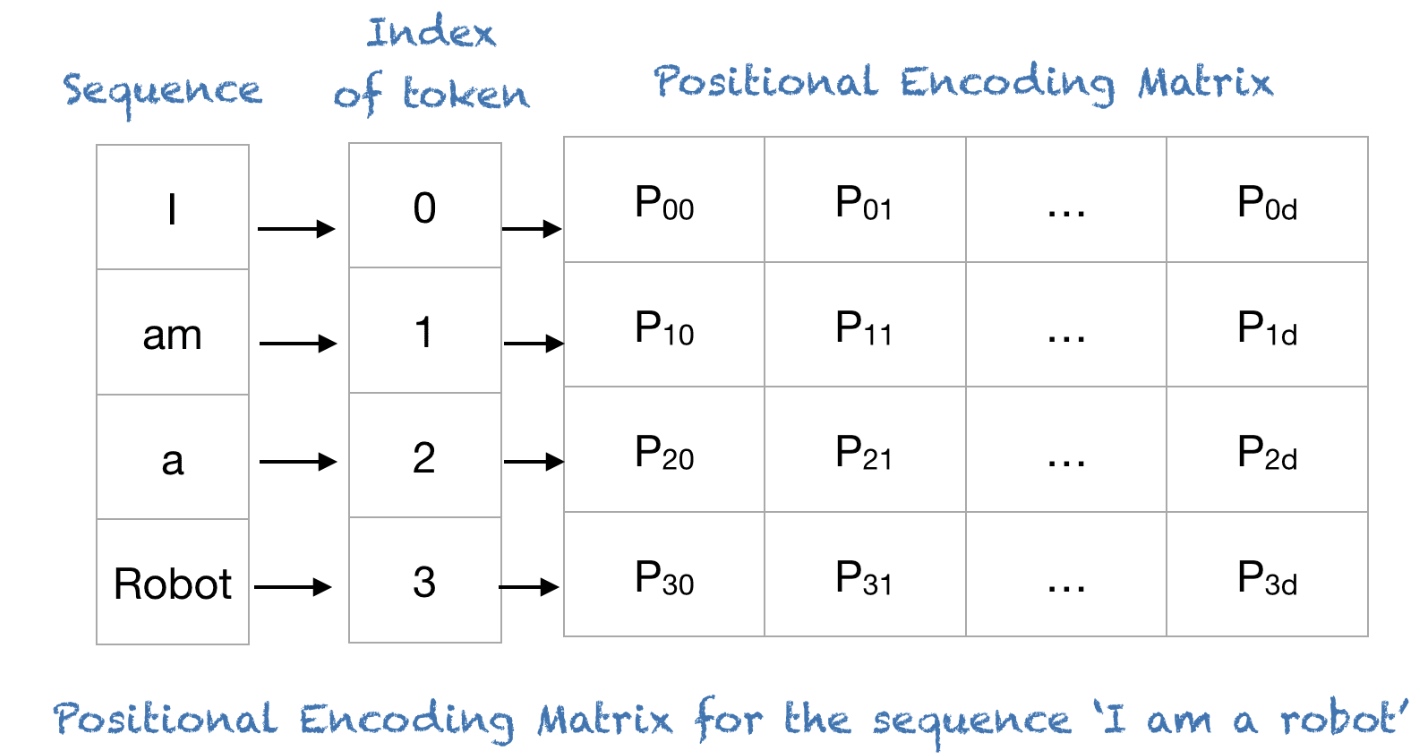
world_sizerankDistributedSampler时,torch.util.data.Dataloader创建时的shuffle参数,相当于把随机的功能交给了DistributedSampler。默认为Truenum_replicas整除;为False的话Sampler为增加额外的indices;默认为Falseposition embedding,
embedding的方法采用了sinine和cosine来进行。
I am a robot进行编码: