详解PyTorch FSDP数据并行(Fully Sharded Data Parallel)
1. 背景介绍
全切片数据并行(Fully Sharded Data
Parallel,简称为FSDP)是数据并行的一种新的方式,FSDP最早是在2021年在FairScale-FSDP中提出的,后来合入了PyTorch
1.11版本中。微软之前Deepspeed框架中提出过三种级别的ZERO算法,FSDP可以看成是ZERO-3的实现。
详解MegatronLM序列模型并行训练(Sequence Parallel)
1. 背景介绍
MegatronLM的第三篇论文【Reducing Activation
Recomputation in Large Transformer
Models】是2022年出的。在大模型训练过程中显存占用过大往往成为瓶颈,一般会通过recomputation重计算的方式降低显存占用,但会带来额外的计算代价。这篇论文提出了两种方法,分别是sequece parallel和selective activation recomputation,这两种方法和Tensor并行是可以相结合的,可以有效减少不必要的计算量。
下图中绿色部分表示不同模型中需要用于保存activation需要的显存大小,蓝色部分表示不同模型中需要用于保存parameter和optimizer state需要的显存大小。红色线表示A100的显存大小80G。
详解MegatronLM Tensor模型并行训练(Tensor Parallel)
1. 背景介绍
MegatronLM的第一篇论文【Megatron-LM: Training
Multi-Billion Parameter Language Models Using Model
Parallelism】是2020年出的,针对billion级别的模型进行训练,例如具有38亿参数的类GPT-2的transformer模型和具有39亿参数的BERT模型。
分布式训练的模型并行有两种方式,一种是层间并行(inter-layer),也就是Pipeline流水线并行,相当于下图对整个模型竖切后每个device各保存3个layer(0,1,2和3,4,5);一种是层内并行(intra-layer)的方式进行,也就是Tensor模型并行,相当于下图横切后每个device各保留6个layer的一半。
详解MegatronLM流水线模型并行训练(Pipeline Parallel)
1. 背景介绍
MegatronLM的第二篇论文【Efficient Large-Scale
Language Model Training on GPU ClustersUsing
Megatron-LM】是2021年出的,同时GPT-3模型参数已经达到了175B参数,GPU显存占用越来越多,训练时间也越来越长。
Megatron-LM源码系列(一):模型并行初始化
在本系列中,我们将探讨Megatron-LM的源代码。Megatron-LM是由Nvidia开发的一个大规模语言模型训练框架,它采用模型并行的方式实现分布式训练。在本篇文章中,我们将关注模型并行初始化的过程。
1. pretrain
在Megatron中pretrain函数是框架执行的入口,定义在megatron/training.py文件中。
1 | def pretrain(train_valid_test_dataset_provider, |
以gpt训练为例,在pretrain_gpt.py中使用如下:
1 | if __name__ == "__main__": |
LLM大模型训练加速利器FlashAttention详解
1. 背景介绍
因为Transformer的自注意力机制(self-attention)的计算的时间复杂度和空间复杂度都与序列长度有关,所以在处理长序列的时候会变的更慢,同时内存会增长更多。通常的优化是针对计算复杂度(通过\(FLOPs\) 数衡量), 优化会权衡模型质量和计算速度。
在FlashAttention中考虑到attention算法也是IO敏感的,通过对GPU显存访问的改进来对attention算法的实现进行优化。如下图,在GPU中片上存储SRAM访问速度最快,对应的HBM(high
bandwidth memory)访问速度较慢,为了加速要尽量减少HBM的访问次数。 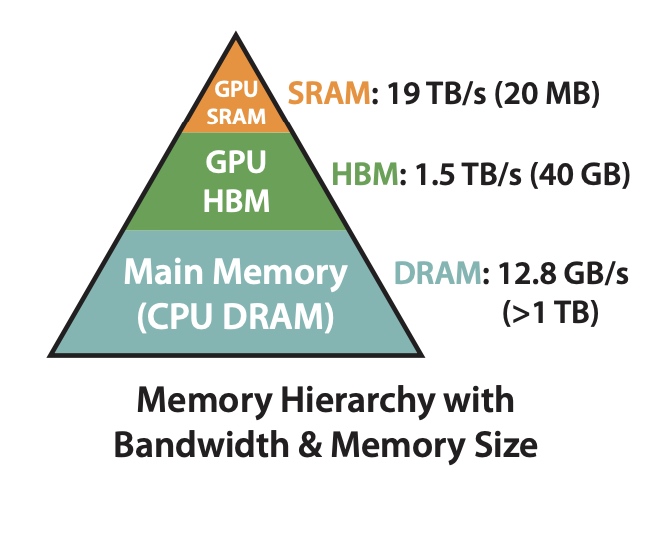
详解大模型微调方法LoRA Adapter(内附实现代码)
1. 背景介绍
以GPT-3
175B参数量为例,过大的参数量在Finetune的时候代价很大,Adapter适配器方法是进行大模型微调的方法之一。Adapter方法的主要思路是在模型网络结构中加入新定义的Adapter适配器部分,在重训的过程中只更新Adapter部分的网络参数。Adapter-based tuning最早源于19年的【ICML2019:
Parameter-Efficient Transfer Learning for NLP adapters】
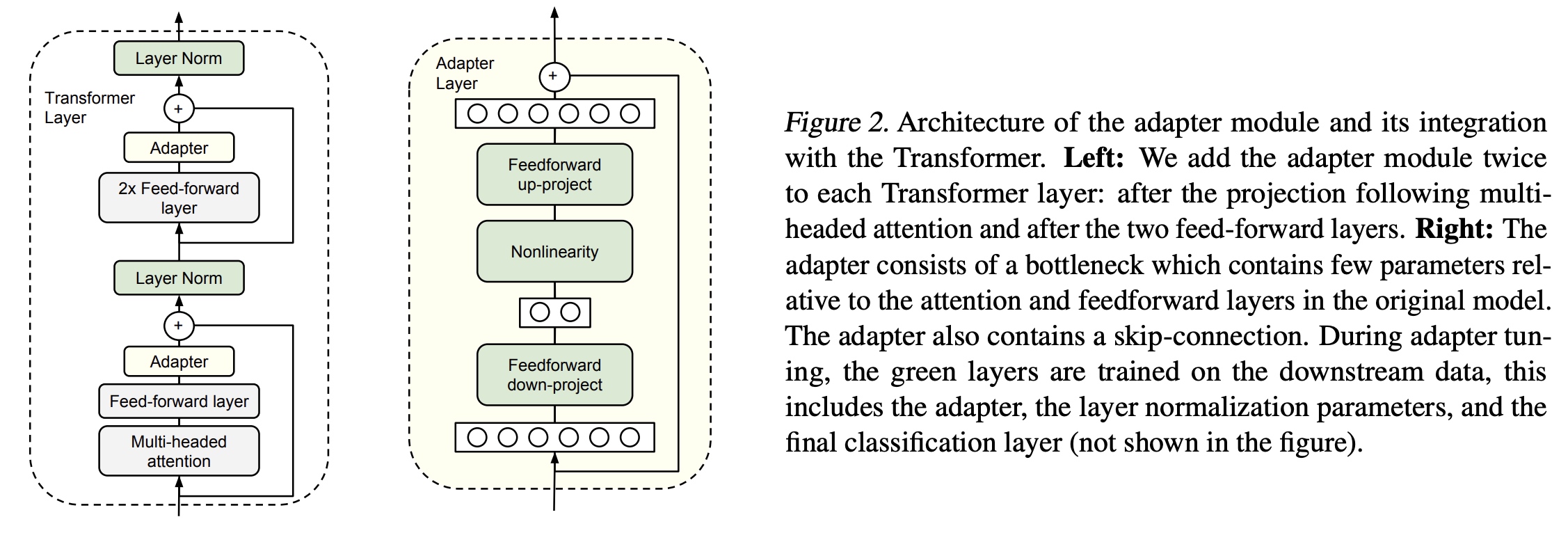
Adapter
module会先把输入的d维向量映射为一个小的m维向量,通过非线性层后,再从m维向量映射回d维向量;其中也用到了残差网络,结构如下图(右):
Adapter的效果可以大幅减少微调的参数量: 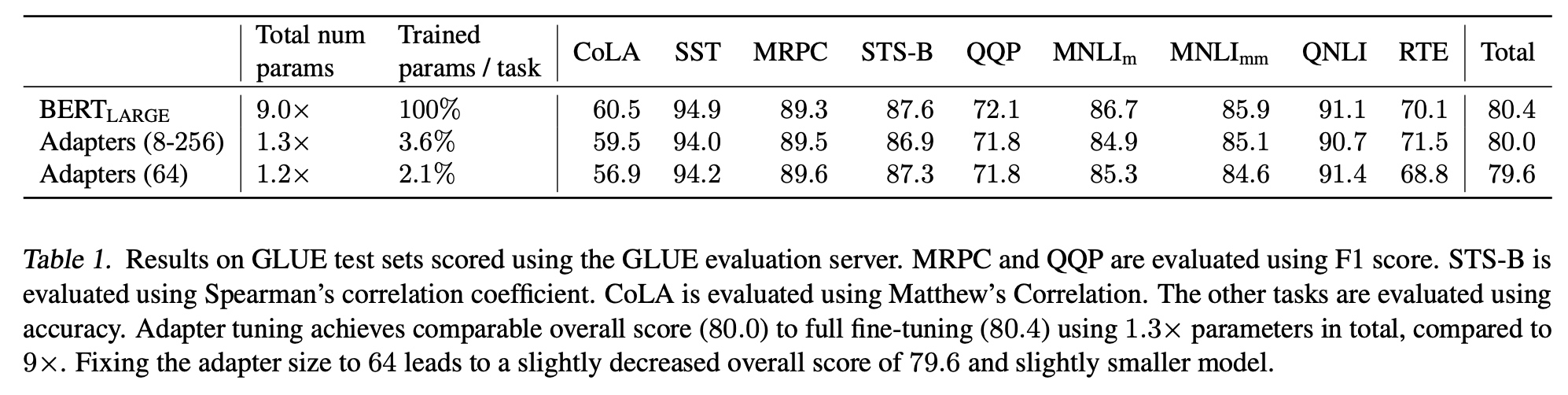
pytorch模型网络可视化画图工具合集
在PyTorch中,有几种不同的工具可以用于网络结构的可视化。下面将以ResNet-18为例,展示如何使用常用的PyTorch画图工具进行网络结构的可视化。
ResNet-18是一个经典的卷积神经网络模型,由多个卷积层、池化层、全连接层和残差连接(Residual
Connection)组成。参考Deep
Residual Learning for Image Recognition,网络结构如下: 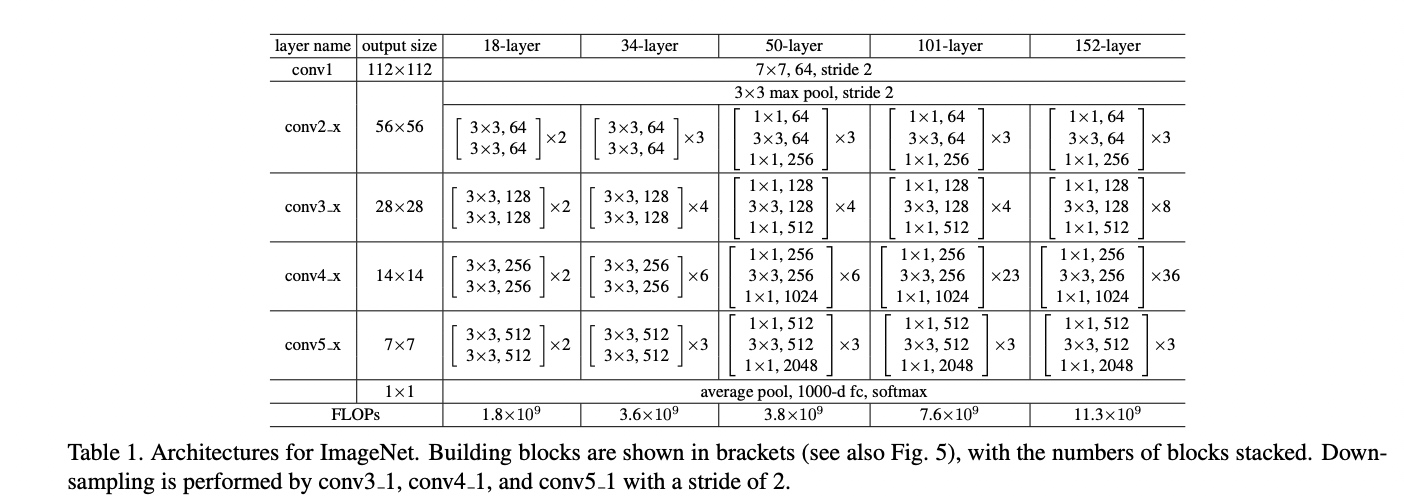
在PyTorch中可以能过torchvision快速使用ResNet-18,使用代码如下:
1 | from torchvision.models import resnet18 |
x是随机生成的输入数据,model是resnet18的实例。
详解大模型微调方法Prompt Tuning(内附实现代码)
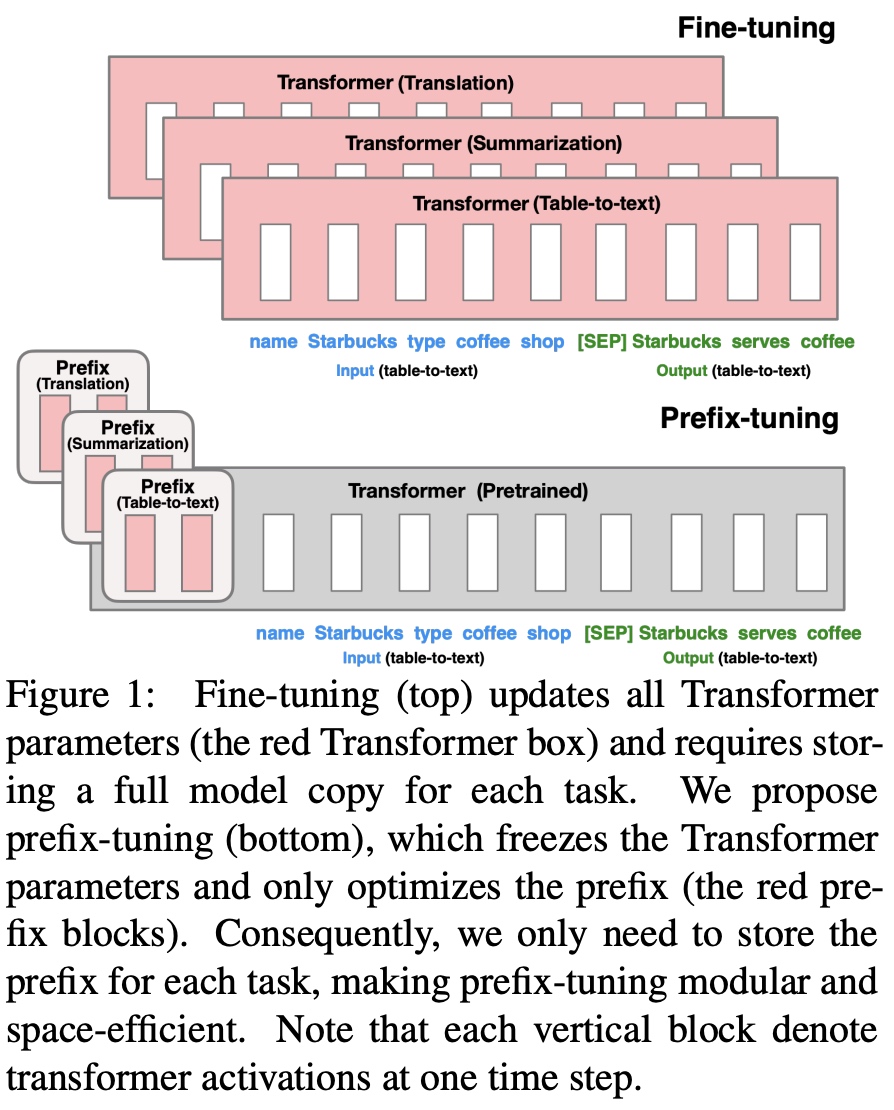
Prompt Tuning是现在大模型微调方法中的一种常用方法,本文通过解读5篇论文来了解Prompt Tuning方法演进的过程。分别是Prefix-Tuning、P-Tuning v1、Parameter-Efficient Prompt Tuning、P-Tuning v2。
1. Prefix-Tuning:Optimizing Continuous Prompts for Generation
Finetuning之前是使用大模型进行下游任务重训的方法,但由于大模型参数量过大,Finetuning需要大量的数据,以及更多的算力去更新学习参数,不够实用。在2021年提出的prefix-tuning算法,并在自然语言生成任务(NLG, Nature Language Generation)上做了验证。这里注意区分下另一个NLP的概念,在NLP中还一类任务叫自然语言理解(NLU, Nature Language Understanding)。
在Prompt思想的启发下,在Prefix-Tuning中提出了给每一个input输入增加一个连续的任务相关的embedding向量(continuous task-specific vectors)来进行训练。