DeepSeek-V3论文
1. 概述
- DeepSeek-V3采用MoE架构,总共
671B参数,每个token会激活37B参数量;训练采用了14.8T Token数,训练耗时为2.788M H800 GPU时 - 跟DeepSeek-V2相同点
- MLA(
Multi-head Latent Attention) - DeepSeekMoE结构
- MLA(
- 跟DeepSeek-V2不同点
- 负载均衡策略: 使用auxiliary-loss-free策略用于负载均衡,减少不均衡对模型性能产生负面影响
- 训练目标:使用了多token预测目标(
Multi-Token Prediction),简称MTP
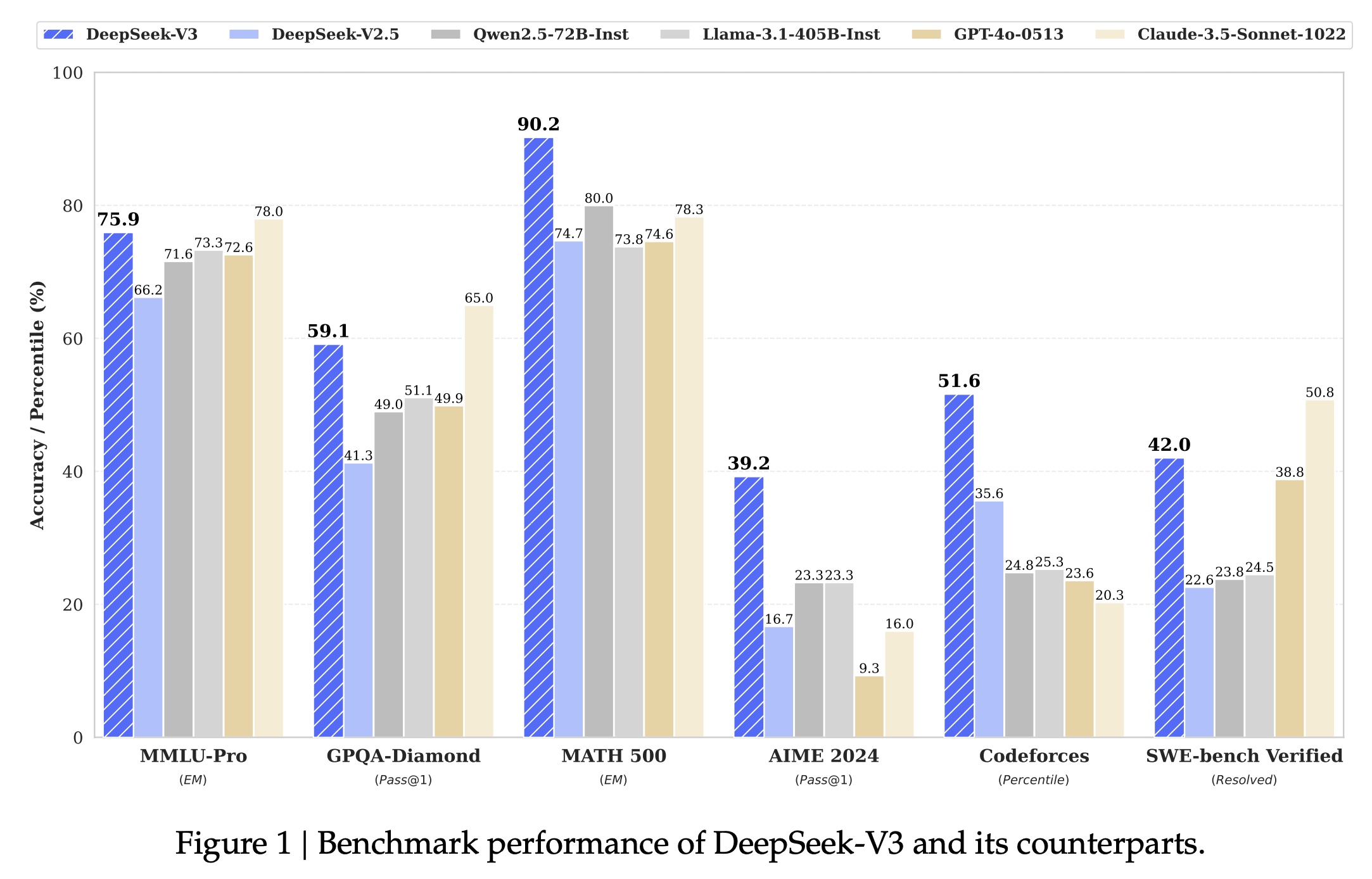
- 各个评测集下的效果: